Filterezés és a mesterséges intelligencia tanítása – címkéző algoritmus fejlesztése a kulisszák mögött III.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Mindössze két hónap állt rendelkezésére a fejlesztőknek és a jogász szakértőknek a projekt során arra, hogy egy jól működő címkéző algoritmust hozzanak létre.
A bírósági határozatok pertárgy szerinti kategorizálása meglehetősen hasznos tud lenni a jogászok számára a forráskutatási munkájuk során, ugyanis a jogi keresők találati listája sok esetben nem tartalmaz minden releváns találatot. A pertárgy szerinti kereséssel azonban a hasonló témájú ügyek együttesen vizsgálhatóvá válnak. A bírósági határozatok pertárgy szerinti csoportosítása azonban nem egy egyszerű feladat, manuálisan történő címkézésük ugyanis jelentős mennyiségű emberi munkaórát vesznek el, ráadásul az eredmények sem lesznek konzisztensek. A Jogtárat kiadó Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. ezért közösen kifejlesztett egy gépi tanuláson alapuló bírósági határozatokat pertárgy szerint automatikusan címkéző algoritmust. Az előző cikkben bemutattuk a módszerek és eszközök egy részét, amit a fejlesztéshez használtunk: az adathalmaz sajátosságait, a címkerendszer elkészítését, valamint a természetesnyelv-feldolgozás olyan sajátosságait, mint a vektorizálás, az előfeldolgozás és a dimenziócsökkentés. Ebben a részben bemutatjuk a további általunk használt eljárásokat: a negatív filterezést, a tanítási, valamint az iterálási folyamatot. A következőkben pedig kitérünk a fejlesztés során tett megállapításainkra.
A negatív filterezés
A jelenlegi fejlesztés során a multi-label kategorizálást (aminek a sajátosságairól ennek a cikksorozatnak az első részében lehet olvasni) úgy fogtuk fel, hogy minden egyes kategória esetében egy bináris klasszifikálót készítettünk el. Ez azt jelenti, hogy végső soron az algoritmusnak minden egyes dokumentum esetében minden, az adott jogterület esetében releváns kategóriára el kellett dönteni, hogy a dokumentum beletartozik-e vagy nem. Így egy dokumentum akár több címkét is felvehet, vagy akár egyet sem (ez esetben „egyéb” címke alá soroltuk). Egy ilyen bináris megközelítésű gépi tanulási folyamat esetében fontos, hogy mind pozitív, mind pedig negatív példából elegendő álljon rendelkezésre a tanítás során, tehát kellenek olyan dokumentumok, amik biztosan az adott kategória alá tartoznak és olyanok, amik biztosan nem.
Jelen esetben, a bírósági határozatok kategorizálása során csak a pozitív minták voltak ismertek, amik egy adott kategória alá tartozhatnak, a negatív mintához pedig alapvetően azokat soroltuk, amik nem tartoztak az adott címke alá. Azonban azt a projekt előző cikkben bemutatott sajátosságai miatt nem tudtuk biztosan kijelenteni, hogy az összes pozitív mintát felcímkéztük az adott kategória vonatkozásában, így potenciálisan a negatívként kezelt minták is tartalmazhattak pozitív adatokat. Ezért ebben a projektben úgynevezett negatív filterezési eljárást alkalmaztunk.
A negatív filterezés azt jelenti, hogy a negatív minták közül kiszűrjük azokat a dokumentumokat, amik bizonyos előre meghatározott jogi kifejezések vagy jogszabály-hivatkozások miatt nagy valószínűséggel megállapíthatóan az adott pertárgy kategóriába tartoznak. Ezzel az eljárással tehát meg tudtuk tisztítani a negatív mintákat, hogy nagyobb arányban tartalmazzon biztosan olyan dokumentumokat, amelyek nem tartoznak az adott kategória alá, így a gépi tanulás hatékonyságát tudtuk növelni. Az így kiszűrt dokumentumokat aztán sem a pozitív, sem pedig a negatív mintákhoz nem soroltuk be a tanítás során.
Természetesen az ilyen negatív filterezési eljárással óvatosan kell bánni, tehát olyan kifejezések, amelyek széleskörűen használatosak több pertárgy esetében vagy például olyan jogszabály-hivatkozás, amelyek adott esetben akár több témába tartozó bírósági határozatokat átfednek (mint az eljárási vagy az illetékkel kapcsolatos szabályok) nem használhatóak ebben az eljárásban. Fontos, hogy minden releváns kifejezés a mintafájlok között maradjon, hiszen ezzel a gépi tanulási algoritmus előrejelzését könnyítjük meg. Ugyanez igaz a jogszabály-hivatkozásokra is, hiszen van pár olyan jogszabály, aminek a megléte egyértelműen, vagy legalábbis igen nagy eséllyel képes determinálni a dokumentum adott pertárgy kategória alá tartozását.
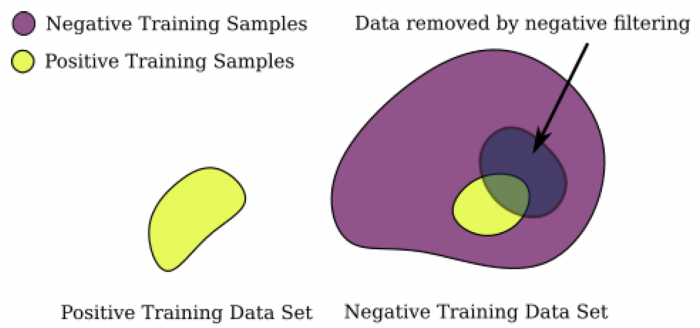
A negatív filterezés eljárás lényege vizualizálva: a negatív mintákat megtisztítjuk a potenciálisan pozitív dokumentumoktól
Tanítás
Ahogy említettük, a kialakított kategóriarendszer mind a 167 elemére külön bináris modellt tanítottunk le. Figyelembe véve, hogy egyes kategóriák több jogterületet is átfedtek, ilyen esetekben minden jogterületre külön lefejlesztettük a modellt az adott kategóriára nézve, így összesen 229 különböző bináris klasszifikáló modellt elkészítve. Az algoritmust úgy állítottuk be, hogy maximum 4 különböző címkét tegyen egy dokumentumra a lehetséges 167-ből.
A gépi tanulással kapcsolatos nemzetközi szakirodalomban egyöntetű az az álláspont, hogy a kontextus függő beágyazásokon (mint a BERT), vagy más mélytanuláson alapuló megközelítések hatékonyabbak lehetnek, mint a hagyományos gépi tanulási módszerek. Mi ennél a projektnél mégis a különböző hagyományos módszereket hasonlítottuk össze. Egyrészt azért, mert a jogi informatikai szakirodalomból az tűnik ki, hogy az olyan algoritmusok, mint a Support Vector Machine (SVM) vagy a Logistic Regression (LR) egyszerű, de hatékony megoldást jelentenek hosszú jogi szövegek kategorizálása esetén, ráadásul bizonyos esetekben még a mélytanulás alapú megoldásokat is képesek felülmúlni. Másrészt pedig azért, mivel a hagyományos gépi tanulási megoldások sokkal gyorsabban felépíthetők, mint a mélytanulásos társaik, nekünk pedig összesen két hónapunk volt a projektre és arra, hogy több, mint 200 modellt letanítsunk.
Így végül 5 különböző gépi tanulási algoritmust próbáltunk ki és hasonlítottuk össze a hatékonyságukat: lineáris kerneles SVM, Naive Bayes (NB), Logistic Regression, Nearest Neighbour (NN) és Random Forest (RF) [ezeknek a rövid magyarázata a cikk végén található].
A modellek kiértékeléséhez kétszer megismételt, úgynevezett 10 részre osztott keresztvalidálási eljárást használtunk. Ez azt jelenti, hogy az adathalmazt 10 egyenlő részre osztjuk, majd 9 részen elvégezzük a tanítást, a maradék részt pedig tesztelésre használjuk. Ezt az eljárást aztán 10-szer egymás után megismételjük úgy, hogy minden esetben más rész marad meg tesztelésre. Ezt követően pedig átlagoljuk a megkapott eredményeket.
A kiértékeléshez az F1 mértéket használtuk, ami jelen esetben nem az autóversenyt jelentette, hanem egy statisztikában bevett mérőszám, ami a pontosság és a fedés harmonikus közepe.
A pontosság az információ kinyerésben és a klasszifikálásban használt mérőszám, amely azt mondja meg, hogy a visszaadott elemek közül mekkora arányban vannak a releváns adatok (tehát amik megfelelnek a keresési követelményeinknek), míg a fedés azt mondja meg, hogy mennyi releváns dokumentumot talált meg a rendszer az összes releváns közül. Egy jogi keresés során mindkettő fontos lehet, ezért használtuk az F1 pontszámot.
A különböző gépi tanulási módszerek összehasonlításához a „Munkaviszony megszüntetése” pertárgyat választottuk, mert ehhez elegendő mennyiségű tanítóadatot találtunk (több, mint 5000 pozitív mintát), ráadásul volt annyira specifikus, hogy a negatív minták is jól elkülöníthetőek voltak tőle a munkajogi jogterületen belül. Az eredményekből pedig azt állapítottuk meg, hogy a lineáris kerneles SVM megoldás bizonyult a leghatékonyabb algoritmusnak, hiszen 93,5%-os F1 pontot ért el. Így a továbbiakban ezt a megoldást alkalmaztuk a többi pertárgy esetében is. Emellett pedig bebizonyosodott az ún. „2 grammos” (szópárokat figyelembe vevő) vektorizálás hatékonysága is, mert minden modell jobb eredményeket ért el, mint az „1 grammos” változat esetében (tehát amikor csak egyes szavakat veszünk figyelembe).
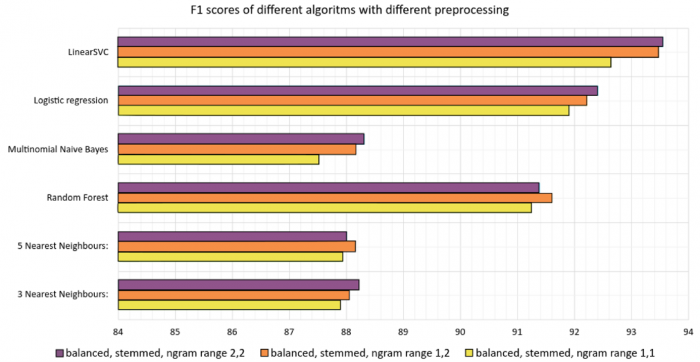
Az egyes gépi tanulás alapú megoldások eredménye a „Munkaviszony megszüntetése” pertárgy esetében figyelembe véve a különböző előfeldolgozási és vektorizálási módszereket is
Iteratív címkézés
Miután az egyes modellek letanítottuk, a gép által pozitív mintába sorolt dokumentumokat ellenőriztettük egy jogi szakértővel, hogy azok valóban abba az adott pertárgyba tartoznak-e. Ezt követően a jóváhagyott dokumentumokat hozzáadtuk a pozitív halmazból, a fals találatokat pedig töröltük, és ez alapján újra lefuttattuk a tanulást. Ez ugyan jelentősen időigényes feladat volt, hiszen mint már korábban is írtuk, az ilyen kézi címkézési folyamat meglehetősen hosszú időt vehet igénybe. Viszont azoknak a kategóriáknak az esetében, ahol eredetileg 20 és 100 között volt a pozitív dokumentumok számossága, valamennyit javítani tudtunk a teljesítményükön.
A cikksorozat jövő héten folytatódik – kövessék figyelemmel, hogy milyen eredményekre jutottak a fejlesztés során az algoritmust készítő szakemberek.
Szómagyarázat
- Bidirectional Encoder Representations from Transformers (BERT): A BERT a Google által fejlesztett nyelvi modell, amelyet széleskörűen lehet alkalmazni többféle természetesnyelv-feldolgozási feladat során. A BERT abban különbözik a korábban használt vektorizálási módszerektől, hogy képes többek között a kontextust, szórendet is figyelembe vevő vektorforma előállítására is. Remekül alkalmazhatóak névelem-felismerésre, de egy fontos limitációval rendelkeznek: alapvetően csak rövidebb, legfeljebb 512 token hosszú szövegekre alkalmazhatók egyszerűbben, bár ezen a területen folyamatosan fejlesztéseket és javításokat végeznek.
- Mélytanulás (deep learning): A mélytanulás a gépi tanulás alapú megoldások egyik alága, ami lényegében három vagy több rétegű neurális hálókat használ. A mélytanulás a mesterséges intelligencia fejlesztéseknek az a része, amely az emberi agy viselkedését kívánja szimulálni, legalábbis azt a részét, hogy képes legyen „tanulni” nagy mennyiségű adatból. A mélytanulásra építő megoldások képesek munkafolyamatokat automatizálni, illetve bizonyos elemzői vagy fizikai feladatot elvégezni emberi közbeavatkozás nélkül. Mélytanuláson alapuló eszközöket alkalmaznak többek között a hangirányításos eszközökben, a hitelkártya csalások felismerésében, valamint az önvezető autókban.
- Support Vector Machine (SVM): az SVM olyan gépi tanulási algoritmus, amit klasszifikálási illetve regressziós feladatok esetén használnak gépi tanulás alapú projektekben. Klasszifikálás esetén a különböző kategóriákhoz tartozó adatokra képes olyan felületet illeszteni, ami a leghatékonyabban elszeparálja a különböző kategóriába tartozó adatokat. Az SVM a felügyelt gépi tanulási módokhoz tartozik, ami azt jelenti, hogy a tanításhoz szükség van az adatokhoz tartozó címkékre.
- Lineáris kernel: A lineáris kernel az SVM gépi tanulási algoritmus során illesztett felület egyik gyakran alkalmazott fajtája, amely segítségével egy sík felületet (hipersíkot) illeszthetünk az adatpontokra.
- Naive Bayes (NB): A Naive Bayes klasszifikáló a valószínűségi klasszifikálók családjába tartozik. A valószínűségi klasszifikálók lényege, hogy képes meghatározni az adott adathalmaz lehetséges felosztását a megadott kategóriarendszer alapján ahelyett, hogy csak egy címkét rakna az adathalmaz tagjaira. Feltételezi, hogy a változók (esetünkben a szavak, szópárok) egymástól függetlenek, amely nyilvánvalóan nem teljesül az esetek többségében, de ennek ellenére a dokumentumok klasszifikálása esetén jól tud teljesíteni.
- Logistic regression (LR): Neve alapján azt gondolhatnánk, hogy regresszió típusú feladatok megoldására alkalmazható algoritmus, azonban ennek pont az ellenkezője igaz, hiszen ez egy klasszifikálási algoritmus. A logisztikus regresszió segítségével lehetséges megbecsülni egy bizonyos esemény bekövetkezésének (esetünkben, hogy az adott dokumentum egy bizonyos pertárgyhoz tartozik-e) valószínűségét. Egy függő változó (Adott pertárgyhoz tartozik a dokumentum vagy nem) és a független változók (itt a dokumentumban előforduló szavak szópárok) közötti kapcsolat leírására szolgál.
- K-nearest neighbor (KNN): A KNN egy közelségen alapuló gépi tanulási algoritmus. A címkézést aszerint végzi el, hogy a legközelebbi K db legközelebbi dokumentum milyen címkével rendelkezik, és azt a címkét adja, amelyikből a legtöbb volt. A jogi szövegbányászatban ez a gyakorlatban azt jelenti, hogy ha van egy összetartozó kategóriahalmazunk, akkor ez a modell képes lehet megtalálni a többi olyan dokumentumot, amely a szövegben található kifejezések, megfogalmazások vagy bizonyos definiált névelemek alapján ugyanabba a kategóriába tartoznak.
- Random Forest (RF): gépi tanulási algoritmus, amelyben részadatokon döntési fákat tanítunk, majd az egyes fák együttes “szavazatát” lehet felhasználni az osztályozáshoz, amelyek eldöntik, hogy melyik lehetséges kategóriába vagy kategóriákba tartozik az adott szöveg.


A kutatásról készült teljes, angol nyelvű tanulmány ingyenesen letölthető innen.
A tanulmány szerzői:
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója
- Üveges István, a Szegedi Tudományegyetem Nyelvtudományi Doktori Iskolájának doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója
- Orosz Tamás PhD, szoftverfejlesztő mérnök
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője