A mesterséges intelligencia vizsgáztatása – jogi címkéző algoritmus fejlesztése a kulisszák mögött IV.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Hogyan teljesített a címkéző algoritmus a bírósági határozatok esetében? Milyen eredményeket ért el adat augmentálással a jogászokból és fejlesztő szakértőkből álló csapat? A cikkből további érdekességek derülnek ki a gépi tanulás jogi szövegre történő adaptálásáról.
Cikksorozatunkban mélységében mutatjuk meg, hogy hogyan lehet jogi címkéző algoritmust fejleszteni, és a jól hangzó gépi tanulás, mesterséges intelligencia kifejezések mögött milyen komoly munkát igénylő kísérletező kutatás, modellezés és tesztelés folyik egy-egy projekt során.
A Jogtárat kiadó Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közösen kifejlesztett gépi tanuláson alapuló algoritmusa a bírósági határozatokat pertárgy szerint automatikusan címkézi (vagyis kategorizálja), ami azért nagyon hasznos és hiánypótló, mivel az ügyvédek és más jogászi munkát végző szakemberek egyes ügyekhez történő forráskutatási munkáját jelentősen pontosítja és gyorsítja azáltal, hogy sokkal relevánsabb találatokat ad a kereső, és ráadásul a hasonló témájú ügyek együttesen vizsgálhatóvá válnak.
A cikksorozat előző részeiben bemutattuk, hogy mi az az alapprobléma, amit megoldottunk ezzel a fejlesztéssel, valamint hogy milyen eszközöket és módszereket használtunk a fejlesztés során. Ebben a cikkben bemutatjuk, hogy melyek azok a főbb eredmények, amiket egy ilyen gépi tanuláson alapuló mesterséges intelligencia fejlesztés során megállapítottunk.
Eredmények
Magának a címkéző algoritmusnak a hatékonyságát (összehasonlítva a kézi címkézés teljesítményével különböző emberi csoportok esetében) a korábbi cikksorozatunkban már bemutattuk. Akkor arra jutottunk, hogy az algoritmus bizonyos esetekben már képes elérni a leginkább hozzáértő szakértő teljesítményét is, illetve minden esetben azt tapasztaltuk, hogy a gépi címkézés képes növelni a hatékonyságát az egyes csoportoknak. Ebben a cikkben kicsit hátrébb lépünk, és azt mutatjuk be, hogy az előző két cikkben bemutatott fejlesztés során használt módszerek és eszközök milyen számszerűsíthető és bemutatható eredményeket értek el. Egy gépi tanuláson alapuló fejlesztéshez sokféleképpen hozzá lehet ugyanis állni, sok módszert lehet használni és sok mindent figyelembe kell venni. Ezzel a cikkel remélhetőleg hozzájárulunk ahhoz, hogy az ez iránt érdeklődők választ kapjanak arra, milyen szempontok szerint kell elkezdeni egy ilyen típusú fejlesztést.
A tanításhoz szükséges minimális dokumentumszám meghatározása
Ahogy ennek a cikksorozatnak a 2. részében is írtuk, egy felügyelt tanításon alapuló kategorizáló algoritmus fejlesztésének a lényege, hogy úgy tanítjuk az algoritmust, hogy betáplálunk bizonyos mennyiségű adatot, és elmondjuk, hogy milyen kimenetelre számítunk, hogy az algoritmus képes legyen „rátanulni” az adatnak azokra az attribútumaira, amely alapján nagy eséllyel meg lehet jósolni, hogy az az adott kategóriába tartozik. Ehhez pedig bizonyos mennyiségű tanítóadatra van szükség. Főszabály a mesterséges intelligenciával kapcsolatban, hogy minél több tanítóadat áll a rendelkezésünkre, annál jobb lesz az algoritmus teljesítménye, viszont hogy mennyi az a minimális dokumentummennyiség, amivel már elfogadható hatékonyságú algoritmust lehet létrehozni, az projektek szerint változhat. A magyarországi jogi informatikai fejlesztések korlátaival kapcsolatban sokszor elő szokott jönni, hogy a hazai intézmények nem rendelkeznek megfelelő számú adattal egy mesterséges intelligencia projekthez, ezért sokszor bele sem vágnak egy ilyenbe. Ezért mértük le a bírósági határozatok pertárgy szerinti kategorizálása kapcsán, hogy mennyi adatra van szükségünk minimálisan, hogy pontos képet kapjunk ezzel kapcsolatban, és hogy esetleg el tudjuk oszlatni az ezzel kapcsolatos félreértéseket.
A minimális dokumentummennyiség meghatározásához egy viszonylag nagy elemszámú címkét a „Munkaviszony megszüntetése” kategóriát választottuk, amihez nagyjából 5000 pozitív tanítóadatot le tudtunk szűrni a manuális pertárgy megnevezések általánosítása és bizonyos szabályalapú szűrők alapján. Azért volt fontos, hogy nagy elemszámú kategóriát válasszunk, mert így a tanítóadatok számosságának logaritmikus skálázásával össze tudtuk hasonlítani, hogy a különböző mennyiségű tanítóadatok hogyan hatnak az algoritmus teljesítményére. Ez azt jelenti, hogy először 10, majd 20, 50, 100, 200 végül pedig 500 darab dokumentumot használtunk fel tanítóadatnak. A modell, amit feltanítottunk, az előző cikkben bemutatott lineáris kerneles SVM, a kiértékelés során pedig a szintén az előző cikkben bemutatott 10 részre osztott keresztvalidálási eljárást használtuk.
Az alábbi ábra ennek alapján azt mutatja, hogy 50 dokumentumnál érünk el egy törést a görbében, ami azt jelenti, hogy már az afeletti tanítóadat számnál nem nő lényegesen a kategorizálás hatékonysága. 50 pozitív dokumentum felhasználásával pedig már 90% közeli F1 értéket sikerült elérni, sőt, 20 tanítóadatnál is már 80% feletti az F1 pont. Ez azt jelenti, hogy már 20-50 dokumentum esetén is jó hatásfokú gépi tanulási algoritmust lehet létrehozni, ami nem annyira jelentős adatmennyiség. Természetesen a projekt sajátosságai ezt a számosságot módosíthatják.
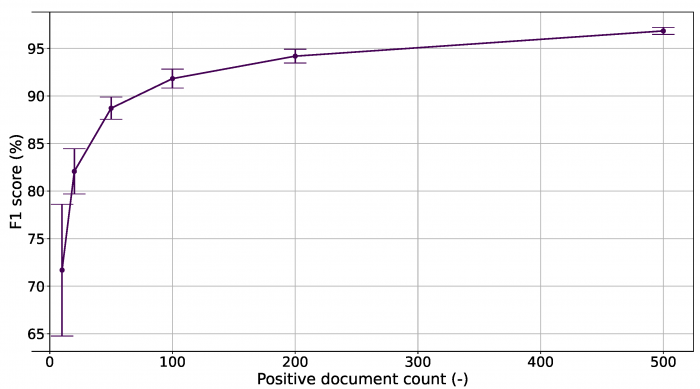
A tanításhoz használt pozitív dokumentumok számosságának hatása a kategorizáló algoritmus teljesítményére
Adat augmentálás
Ugyan a kialakított címkerendszer kategóriáinak 2/3-ához tartozott legalább 50 darab bírósági határozat, azonban így is volt jelentős mennyiségű olyan kategória, amelyhez nem volt meg a megfelelő minimális mennyiségű tanítóadat. Ennek a problémának az áthidalására alkalmas az adat augmentálás, ami azt jelenti, hogy az eredeti adathalmazhoz hasonló új szintetikus adatokat hozunk létre a már létező adathalmaz kis módosításával, ezzel megnövelve azt az adatmennyiséget, amit a gépi tanulás során tanítóadatként lehet használni.
A fejlesztés során az úgynevezett Easy Data Augmentation (EDA) szöveg augmentálási módszert használtuk, ami véletlenszerű törlést, véletlenszerű beillesztést, szinonima helyettesítést, valamint véletlenszerű szócserét használ. Viszont mivel a jogi fogalmak meghatározott szórendet követnek, és mi a tanítás miatt meg akartuk tartani ezt, ezért ennek a módszertannak a véletlenszerű szócsere funkcióját nem használtuk. Ezt a módszertant azért is választottuk, mert korábban sikeresen alkalmazták magyar politikai szövegek szentimentanalízise során. Maga a módszertan egyébként nyilvánosan elérhető és felhasználható Python csomagként.
A fejlesztés során fontos volt azonban mindenekelőtt megvizsgálni, hogy ennek az augmentálási eljárásnak milyen hatása van a modell hatékonyságára, ugyanis a mesterséges adatok létrehozása nem csak javítani, de rontani is tudja a gépi tanulási modell pontosságát. Túl szép is lenne ugyanis, ha nagyon kevés valódi adatból sok szintetikus adatot elő tudnánk állítani, hiszen így egy csapásra megoldódnának a mesterséges intelligencia fejlesztésekkel kapcsolatos problémák. A mesterségesen előállított adat és a valódi adat arányának megtalálása így egy nagyon fontos sarokköve a gépi tanulási fejlesztéseknek.
A megfelelő arányszám megtalálásához ebben az esetben is a „Munkaviszony megszüntetése” címke különböző dokumentumszámosságú pozitív mintáit használtuk. Az ehhez a kísérlethez használt kiinduló darabszámok a következőek voltak: 10, 20, 50, 100, 250 és 500 darab dokumentum. Az augmentálás hatását ezt követően úgy mértük le, hogy az eggyel magasabb számosságra augmentáltuk az adatokat, tehát 10 dokumentumból mesterséges módon előállítottunk annyit, hogy összesen 20 darab legyen, a 20-ból annyit, hogy 50 legyen, és így tovább. Emellett pedig bizonyos esetekben megvizsgáltuk azt is, hogy milyen hatással van, ha a pozitív és negatív minták aránya 1:1 vagy 1:2,57 (az előbbi azt jelenti, hogy a negatív és a pozitív mintaadatok száma megegyezik, míg az utóbbi a teljes adathalmazra jellemző pozitív negatív címkearányt (Munkaviszony megszüntetése címke és nem ez a címke aránya) hivatott leképezni. Ezzel is azt kívántuk megmérni, hogy melyik módszer a hatékonyabb: ha kiegyenlítjük a pozitív és a negatív dokumentumok darabszámát, vagy ha követjük az adathalmazban lévő arányokat.). Az egyes eljárások eredményeit pedig ebben az esetben is 10 részre osztott keresztvalidálási eljárással határoztuk meg.

Először azt határoztuk meg, hogy hogyan alakul a kategorizáló algoritmus teljesítménye szövegaugmentálást használva összehasonlítva azzal, ha nem használunk augmentálást, csupán az eredeti tanítóhalmazon tanítunk. Ezt úgy határoztuk meg, hogy az eredeti adaton tanított modell F1 pontját összehasonlítottuk az augmentált adaton tanított modell F1 pontjával. Tehát ha az eredeti 10 dokumentumból augmentáltunk 10 dokumentumot, hogy összesen 20 darab dokumentum legyen, akkor az erre a halmazra kapott F1 értéket összehasonlítottuk az eredeti 10 dokumentumra kapott F1 értékkel. A két érték közötti különbséget a lenti ábrán ΔA-val jelöltük (világoskék oszlop). Ezt követően azt mértük meg, hogy az augmentált adathalmaznak milyen a teljesítménye a tanítással kapcsolatban az eredeti adathalmazhoz képest. Tehát az eredeti példából kiindulva, ha az eredeti 10 dokumentumból augmentáltunk 10 dokumentumot, hogy összesen 20 darab dokumentum legyen, akkor ebben az esetben ennek az F1 értékét hasonlítottuk össze azzal a halmazzal, ahol 20 eredeti dokumentumot használtunk fel. A két F1 érték közötti különbség a lenti ábrán a ΔB (lila oszlop):
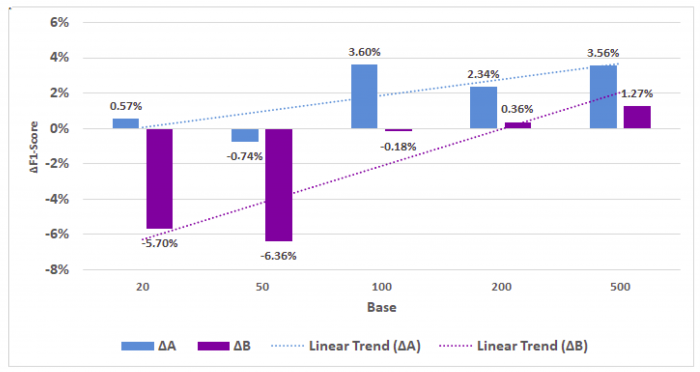
Az F1 pontok közötti különbségek 1:1 pozitív-negatív arányú adathalmazon tanítva Alfa 0,1 és véletlenszerű törlési módszert használva
Az eredmények azt mutatják, hogy augmentált adat hozzáadása az eredetihez majdnem minden esetben javítja a címkéző teljesítményét (ezt mutatja, hogy a világoskék oszlop az esetek többségében pozitív tartományban van). Viszont az is látszik, hogy az augmentált halmaz kis dokumentumszám esetében (100 darabnál kevesebb dokumentum esetén) ugyanakkora elemszámú eredeti dokumentumon tanított algoritmus jelentősen felülmúlja az augmentált adatokon tanítottat, 100 dokumentum után viszont ez az arány kiegyenlítődik (ezt mutatja, hogy a lila oszlopok az első két esetben jelentősen negatívak, míg a többi esetben 0% közeliek).
Az augmentálási eljárásoknak, ahogy a fenti kép aláírásában is látszik, minden esetben van egy alfa paramétere, ami azt jelöli, hogy mekkora hányadát változtattuk meg a szavaknak az augmentálás során. Tehát a 01-es alfa érték például azt jelenti, hogy a szavak 10%-a lett megváltoztatva az eljárás során. Mindezek figyelembevételével az alábbi ábra egy részletes képet mutat arról, hogy a fejlesztés során általunk használt különböző augmentálási eljárások milyen teljesítményt értek el:
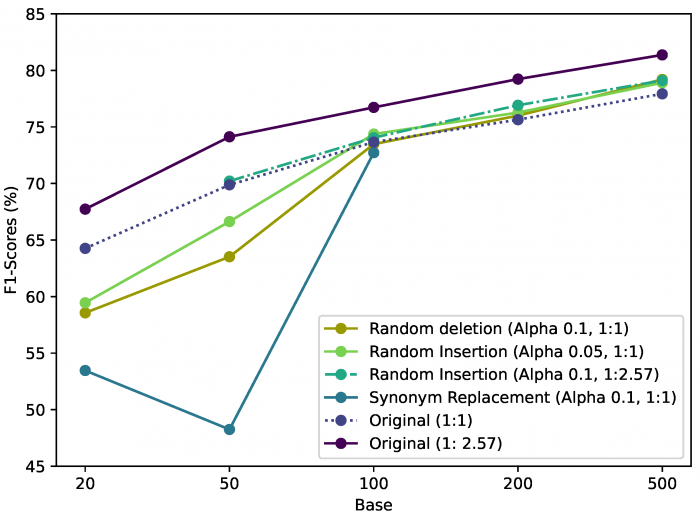
Általános összehasonlítása a különböző augmentálási eljárással készített és az eredeti adatokon történő tanításnak
A negatív filterezés és a validált pozitív tanítóadat hatása az algoritmusra
Ahogy a cikksorozat előző részében írtuk, egy felügyelt gépi tanulási fejlesztés során nem csak az lehet a fontos, hogy a pozitív adatokat ismerjük, hanem az is, hogy a biztosan negatívokat, mert az is segítségül szolgálhat az algoritmusnak a tanítás során. A bírósági határozatok pertárgy szerinti kategorizálása során mi a pozitív adatok nagy részét ismertük, viszont nem tudhattuk biztosan, hogy a negatív adatok nincsenek-e „szennyezve” pozitív adatokkal, ami az algoritmus teljesítményét ronthatja. Ezért egy úgynevezett negatív filterezési eljárással a negatív minták közül kiszűrtük azokat a dokumentumokat, amik bizonyos előre meghatározott jogi kifejezések vagy jogszabály-hivatkozások miatt nagy valószínűséggel megállapíthatóan az adott pertárgy kategóriába tartoznak. Emellett pedig egy iteratív címkézési eljárással a gép által pozitív mintába sorolt dokumentumokat ellenőriztettük egy jogi szakértővel, hogy azok valóban abba az adott pertárgyba tartoznak-e, ezt követően pedig a jóváhagyott dokumentumokat hozzáadtuk a pozitív halmazhoz, a fals találatokat pedig töröltük, és ez alapján újra lefuttattuk a tanítást. Ezzel is a kategorizáló algoritmus hatékonyságát kívántuk javítani.
Az alábbi ábra a negatív filterezés és a pozitív validált tanítóadat hozzáadásának hatását mutatja az algoritmus teljesítményére. A „filtered” a negatív dokumentumok közötti szűrést meglétét vagy meg nem létét jelzi („non-filtered„), míg az updated a validált adat hozzáadását jelenti. Az eredmények azt mutatják, hogy mind a negatív filterezés, mind pedig a validált pozitív halmaz megléte jelentősen képes volt növelni a gépi tanuláson alapuló automatikus kategorizáló teljesítményét. Az oszlopok nagysága ugyanis azt mutatja, hogy a negatív dokumentumok szabályalapú szűrése 10 és 20%-kal képes volt növelni az algoritmus F1 értékét, míg a validált pozitív adat hozzáadása a tanítási folyamathoz 18 és 27%-kal. Az ábrán az is megfigyelhető, hogy a pozitív adat hozzáadásával csökkent az F1 értékek szórása, míg a negatív filterezésnek nem volt ilyen hatása.
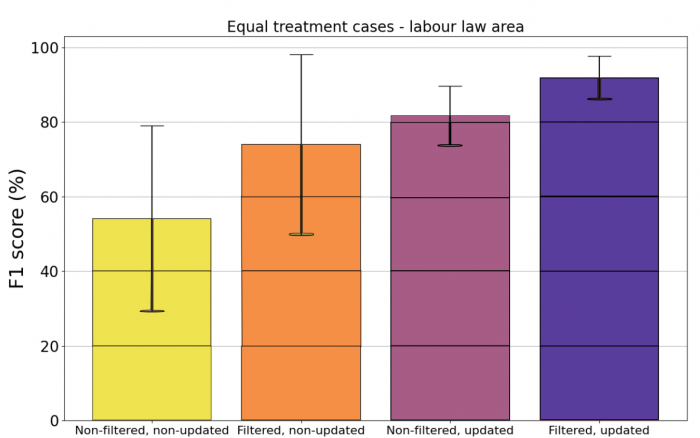
A negatív szűrés és a pozitív validált adatok tanítási folyamathoz való hozzáadásának hatása a gépi tanulási algoritmusra
Algoritmus kiértékelése a kézzel felcímkézett adatokon
Ahogy írtuk, ez idáig az úgynevezett 10 részre osztott keresztvalidálási eljárást használtuk a különböző módszerek hatékonyságának kimérésére. Tekintve, hogy a dokumentumok kézi címkézése egy lassú folyamat, és ha pontos értékeket akarunk kapni, akkor több ember munkája is szükséges hozzá, ez az eljárás tökéletesen alkalmas az egyes módszerek közötti különbség gyors megmérésére. Viszont ez a módszer nem képes helyettesíteni a kézzel előállított tesztadatokon való kiértékelést, ami egyébként a legteljesebb képet képes mutatni a feltanított algoritmus működéséről. Ezért 150 véletlenszerűen választott bírósági határozatokból kézi címkézéssel előállítottunk egy teszthalmazt, amihez már képesek voltunk az algoritmusunk teljesítményét mérni.
Ezt a teszthalmazt két jogi szakértő segítségével állítottuk elő, akik ellenőrizték egymás munkáját annak érdekében, hogy a lehetséges emberi hibák számát minimálisra csökkentsük. Mindezek ellenére az algoritmus eredményei alapján 7 darab dokumentumon találtunk hibát az emberi címkézésben. Ezek közül kettő rosszul volt címkézve, amit javítottunk a gép által felajánlott címkék alapján, egy darab dokumentum olyan címkét kapott, ami az adott jogterületen nem fordulhatott volna elő, négy esetében pedig elírás volt a címke nevében. Ez mutatja azt is, hogy az emberi címkézők milyen visszatérő hibákat képesek véteni, valamint ez abban is megerősített minket, hogy az emberi manuális címkézést sem lehet 100%-ig pontosnak tekinteni, ráadásul emberi munkával a fejlesztés során elérhető több, mint 170 000 bírósági dokumentum felcímkézése nagyjából 8 évet venne igénybe.
Az algoritmus teljesítménye az előállított teszthalmazon a lenti ábrán látható. Kiolvasható belőle, hogy a véletlenszerűen kiválasztott bírósági dokumentumok 57,3%-t teljesen vagy részben jó címkékkel látta el az algoritmus. (A részben történő jó címkézés ebben az esetben azt jelenti, amikor egy dokumentumra több címkét is rá lehetett tenni, és a gép annak egy részét eltalálja.) Körülbelül a dokumentumok 43%-a esetében viszont nem egyezett a gép általi és a szakértő annotátorok általi címkézés. Azonban megvizsgálva a nem egyező dokumentumokat azt vettük észre, hogy a 64 dokumentumból 12 esetében ugyan az annotátorok más címkét adtak, mint a gép, ennek ellenére az nem feltétlenül volt hibás, csak általánosabb címke volt, mint amit az emberek adtak (például az algoritmus a “Gazdasági társaságokkal kapcsolatos ügyek” címkét javasolta, míg az annotátorok a “Cégekkel kapcsolatos ügyek” címkét tették rá a dokumentumra). Ugyanis a kialakított jogi kategóriák nem egymást kizáróak, hanem sok esetben átfedték egymást, így nem csak egy jó válasz fogadható el. A kézi címkézők azonban csupán a legspecifikusabbat tették rá az adott dokumentumra.
Másik 14 dokumentum esetében az algoritmus olyan címkéket adott, amelyek szemantikailag hasonlóak azokhoz a címkékhez, amit a szakértők adtak a dokumentumokra. Például a „Szállítási és fuvarozási szerződés” és a „Nemzetközi fuvarozási szerződés„, valamint a „Gazdasági társaságokkal kapcsolatos ügyek” és a „Cégekkel kapcsolatos ügyek” kategóriák jelentéstani értelemben eléggé közel állnak egymáshoz. Természetesen egy jogi szakértő a jogi háttértudásával pontosan el tudja különíteni ezeket a kategóriákat a bírósági határozatok esetében, egy, a szavak jelentésére építő gépi tanulási modellnek viszont ezek nehézséget okoznak. Így tulajdonképpen a 150-ből 28 olyan dokumentum van, amire megvizsgálva a címkéket és a dokumentumokat azt mondhatjuk, hogy teljesen fals találatokat adott a gép, ami 18,67%-os rontási aránynak számít dokumentum szinten. Ez egyébként megközelíti a korábbi kutatásunkban mért szakértői címkézői teljesítményt (17,28%). Ezeket az eredményeket pedig egy új, ennek a projektnek a tapasztalataira épülő kategóriarendszer kialakításával és új modellek megalkotásával a fejlesztés következő fázisában még sikerült is felülmúlni, amiről majd egy későbbi cikksorozatban fogunk beszámolni.

A gépi tanuláson alapuló kategorizáló algoritmus teljesítménye a 150 kézzel felcímkézett teszthalmazon mérve


A kutatásról készült teljes, angol nyelvű tanulmány ingyenesen letölthető innen.
A tanulmány szerzői:
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója
- Üveges István, a Szegedi Tudományegyetem Nyelvtudományi Doktori Iskolájának doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója
- Orosz Tamás PhD, szoftverfejlesztő mérnök
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője