Jogászok vs. algoritmusok IV.: további eredmények és konklúzió
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Összegezzük a kutatás megállapításait, és megmutatjuk, milyen módon lehetett mérni, hogy mekkora volt az egyetértés az egyes résztvevők kategorizálása során.
Cikksorozatunk első, második és harmadik részét olvasók megismerkedhettek a gépi tanulásra vonatkozó kutatásunk módszereivel, a tanítási folyamattal, és néhány, a LegalTechben (is) fontos technológiai kifejezéssel. Aki idáig eljutott, annak van már némi ismerete arról, hogy mit jelent ebben a kontextusban a címkézős klasszifikálás, a Support Vector Machine, vagy milyen pontossággal dolgoztak ennél az adott gyakorlati problémánál a kísérletben résztvevő jogászok és a „gép”.
Ebben a zárócikkben a kutatás konklúziója ismeretében bemutatjuk az utolsó kérdésre kapott adatainkat is.
Összegzés
A kutatás során tehát megvizsgáltuk, hogy milyen előnyei és hátrányai vannak a gépi tanulásnak az emberi munkával szemben egy olyan monoton munka esetén, mint a jogi dokumentumok kategorizálása, ahol sok esetben a pontos megoldás sem határozható meg. A strukturálatlan vagy félig strukturált jogi dokumentumok felruházása különböző metaadatokkal ugyanis elengedhetetlen ahhoz, hogy az ügyvédek és bírák könnyebben megtalálják a hasonló dokumentumokat, ami nagyban segítheti az egyébként idő- és munkaigényes jogi forráskutatást.
Azonban a jogi szövegek klasszifikálása elképesztően nagy mennyiségű időt vesz el a jogi szerkesztők munkájából. Ezért felmerül a feladat mesterséges intelligencia megoldásokkal történő megtámogatása, azonban egy ilyen fejlesztés idő és költség vonzata sok mindentől függ, így a megtérülést is alaposan meg kell vizsgálni. A kutatásunk célja ezért az volt, hogy összehasonlítsunk egy gépi tanuláson alapuló algoritmust a különböző emberi kategorizálással, mert ha az algoritmus teljesítménye eléri az emberi teljesítményt, akkor esetleg helyettesíteni lehet az emberi munkának ezt a részét.
A kutatás során a résztvevőket három csoportba osztottuk a kompetenciájuk szerint: jogi szerkesztők, jogászok és laikusok. Minden csoportot két részre osztottunk. Az egyik csak olyan dokumentumokat kapott, amik nem voltak előzetesen felcímkézve, míg a másik csak olyan dokumentumokat, amelyeket a gépi tanuláson alapuló kategorizáló algoritmus előzetesen bekategorizált, és azt kellett ellenőrizniük, hogy helyesek-e. Az eredmények azt mutatták, hogy a bevezetett gépi tanuláson alapuló kategorizáló ugyan csak a 49%-át találta meg az összes információnak a dokumentumokban, viszont még ezzel is jelentősen felülmúlta a legkompetensebb csoport, vagyis a jogi szerkesztők átlagos eredményét.
Meglepő módon azok a résztvevők, akik gépi segítséggel kategorizáltak lassabbak voltak, viszont a pontosságuk 50%-kal jobb volt azoknál, akik címkézetlen dokumentumokat kaptak. Továbbá a gépi segítség a laikusok teljesítményét is jelentősen megnövelte, akik így közel azonos eredményt értek el, mint a szakértő résztvevők. Ezek az eredmények így azt mutatják, hogy a gépi tanuláson alapuló módszerek bevezetésének több pozitív hozadéka is lehet. Képesek fejleszteni a munkafolyamatot, csökkenteni a költségeket, növelni az adat minőségét vagy csökkenteni a betanulási idejét az új kollégáknak azáltal, hogy az adat megismerését hatékonyabbá tudják tenni.

A kutatásunkból kiderült tehát, hogy a mesterséges intelligencia sok szempontból képes elérni vagy meghaladni az emberi szakértők teljesítményét, így az ilyen módszerek alkalmasak lehetnek az olyan monoton feladatok elvégzésére, ahol a helyes eredmény megtalálása figyelmet és egyedi szakértelmet igényel, illetve ahol a helyes eredmény sok esetben nem is egyértelmű, mint a jog és így a bírósági határozatok pertárgya esetén. A kutatás emellett azt is megmutatta, hogy a jogi szemléleten túl a teljes adathalmaz megismeréséhez más domain-specifikus tudások és ismeretek is kellenek ahhoz, hogy egy megfelelő kategóriarendszer jöjjön létre. Ez az új típusú adatközpontú szemléletmód képes lehet a jogi adatbázisok használati értékét, illetve kereséseinek hatékonyságát növelni, ezáltal a userek, vagyis az ezt használó jogászok munkáját is közvetve támogatni.
Egy kis extra: a címkézők egyetértése
Ahogy fentebb is és a korábbi cikkekben is említettük, érdekességként kíváncsiak voltunk arra, hogy mekkora az egyetértés az egyes résztvevők kategorizálása, azaz az általuk kiosztott címkék között. A résztvevők közötti egyetértés mérésének célja, hogy képet kapjunk a teljes kategorizálási folyamat megbízhatóságáról. A címkézés közötti egyetértést a Krippendorff alfa nevű mérőszámmal (Kα) mértük le, ami egy gyakran használt statisztikai mutató. Fő különbsége más hasonló módszerekhez képest (például Cohen Kappa, Fliess Kappa) abban áll, hogy lényegében az egyet nem értés kimutatására helyezi a hangsúlyt az egyes résztvevők között. Azért ezt a mérőszámot választottuk az annotáció kiértékeléséhez, mert leginkább ez képes kezelni a bekategorizált adathalmaz nagyságában lévő különbségeket (az egyes résztvevők ugyanis nem ugyanannyi dokumentumot kategorizáltak be a megadott 3 óra alatt), valamint az esetleges hiányzó adatokat és a résztvevők által kiosztott címkék eltérő számosságát. Mindemellett a kapott eredményeket könnyű értelmezni, habár azok magyarázata nem teljesen egységes a szakirodalmon belül. A Kα-t (legegyszerűbb formájában) a következő formulával lehetséges meghatározni:
Kα=1−(D0/De),
ahol D0 a gyakorlatban megfigyelt („tapasztalati-„) egyetértés, De pedig az az érték, amilyen egyetértést akkor mérhetnénk, ha kizárólag véletlenszerűen oszlanának el a címkék az adatsoron, nem pedig az adatok valós tulajdonságai alapján lennének kiosztva. A mérőszám ezen tulajdonsága miatt eredményként a véletlen egyezésen felüli egyetértésről alkothatunk képet a Kα alkalmazásával. Az eredmény minden esetben egy -1 és egy 1 közötti valós szám, ahol 1 a tökéletes egyetértést, 0 a véletlennel megegyező egyetértést, míg a negatív érték a fordított (inverz) egyetértést jelent. Ez utóbbi csak olyan esetekben fordulhat elő, ha a kiosztott címkék valamilyen kategória esetében pontosan az elvárt értékek fordítottjai szerint alakulnak, pl. ha 10 adatból az első öt esetén 1-es, a többi esetén 0-s címkét várunk, az annotáció során viszont az első 5 adat 0-s, a többi pedig 1-es címkét kapna. Ekkor a Kα értéke -1-et venne fel. Emellett érdemes megemlíteni, hogy a viszonylagos konszenzus szerint 0.667 jelenti azt az értéket, ami a legalacsonyabb határa a még elfogadható egyetértésnek, tehát az a minimális szint, amikor kijelenthetjük, hogy a kategorizálás megbízható volt.
Ahogy a következő ábrából is leolvasható, jelen kutatás során ez az érték minden annotátor csoport esetében alacsonyabb volt:
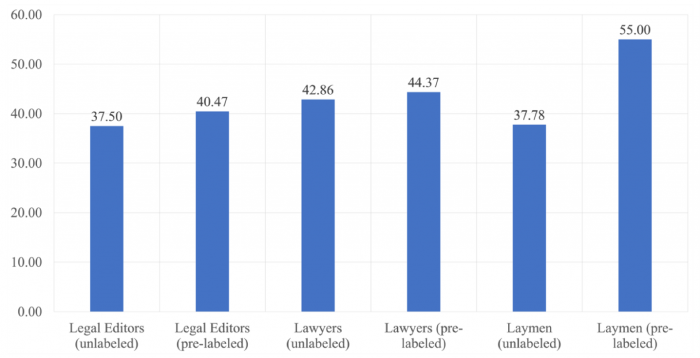
Az egyes résztvevő csoportok közötti egyetértés a Krippendorff alfa értékek * 100 alakban kifejezve
Kirajzolódik továbbá az is, hogy azok a csoportok, akik gépi segítséget kaptak, minden esetben növelni tudták az egyetértést azokkal a csoportokkal szemben, akik címkézetlen dokumentumot kaptak. Ez leginkább a laikusok csoportjainál látszik, akik jelentősen növelni tudták az egyetértést a gépi címkézés igénybevételével a címkézetlen dokumentumokat kapott társaikhoz képest.
Kiemelendő, hogy előre címkézett dokumentumokkal dolgozva (amikor tehát ismert volt előttük egy „javaslat” az algoritmustól) az összes csoport közül ők produkálták a legnagyobb egyetértést.
Ez feltehetőleg annak köszönhető, hogy ők voltak azok, akik a leginkább megbíztak a gép eredményeiben. Ezek az eredmények egyébként további érvként szolgálnak a mesterséges intelligencia alapú megoldások mellett, ugyanis ha a szakértők között is ekkora szórás van a potenciális címkék esetében, akkor sokkal megbízhatóbb tud lenni egy homogén megoldás, még ha az nem is teljesen pontos. Ez utóbbi esetben sokkal határozottabban kirajzolódik a pontatlanság oka, emiatt pedig az gyorsabban és hatékonyabban kijavítható.
Ez a cikksorozatunk véget ért, azonban jövő héten újabb kutatásunk eredményeiről szóló LegalTech sorozattal jelentkezünk, kövessék figyelemmel azt is!


Akiket pedig részletesebben is érdekelnek a jelenlegi kutatásunk eredményei, megtalálhatja a kutatásból készült teljes, angol nyelvű tanulmányunkat itt.
A tanulmány szerzői:
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője
- Üveges István, a Szegedi Tudományegyetem Nyelvtudományi Doktori Iskolájának doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója
- Orosz Tamás PhD, szoftverfejlesztő mérnök
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője