Jogászok vs. algoritmusok III.: az elsődleges eredmények
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Legyőzte-e az emberi csapat a gépet? El lehet-e fedni a jogászok és laikusok közötti kompetenciabeli különbséget a jogi kategorizálás során? Az előzetesen felrakott címkékkel vagy azok nélkül gyorsabb a címkézés folyamata? Legaltech cikksorozatunk folytatódik.
Cikksorozatunkban azt mutatjuk be közérthetően, hogy egy gyakorlati LegalTech problémához kapcsolódó gépi tanulás alapú megoldásnak a hatékonyságát hogyan lehet mérni, és milyen eredményeket lehet elérni.
Az első részben a kutatás alapjai, a második részben az alkalmazott módszerek (kategorizálás, értékelési mérőszámok, résztvevők csoportjai) olvashatók.
Ebben a cikkben az öt fő kérdésből az első négyre vonatkozó eredményeinket mutatjuk be, míg az utolsó részben a maradék eredményeket, valamint a kutatás konklúzióját ismertetjük.
Emlékeztetőül a már jól ismert kérdések:
- Mennyi időbe telik az emberi kategorizálónak felcímkézni a teljes adatállományt (ami a kutatás idején a több, mint 170 000 anonimizált bírósági határozatot jelentette), mennyire képes gyorsítani a folyamatot a gépi támogatás?
- Mennyi információt képes kinyerni az emberi kategorizáló a gép segítségével és anélkül?
- Megbízhatóbban teljesítenek-e a gépi tanuláson alapuló algoritmusok az embereknél a jogi dokumentumok kategorizálása esetén?
- Az algoritmusok képesek-e elfedni a különbségeket a jogi szerkesztők és a jogi szakértelemmel nem rendelkező emberek vagy a nem szerkesztő jogászok között?
- Mekkora az egyetértés a jogi szerkesztők kategorizálása között?
Gyorsaság
Mindenekelőtt tehát arra a kérdésre kerestük a választ, hogy nagyjából mennyi időbe telne, ha az összes anonimizált egyedi érdemi bírósági határozatot kategorizálni szeretnénk, ami, ahogy már említettük, a vizsgálat időpontjában már több, mint 170.000 dokumentumot jelentett. A kutatás során megmértük, hogy a különböző résztvevők három óra alatt mennyi dokumentumot tudnak kategória szerint felcímkézni a potenciális 220 darabból az alapján, hogy milyen szakértelemmel rendelkeznek, illetve előre felcímkézett dokumentumokat kapnak-e vagy sem. Az egyes csoportok átlagos eredményeit a következő ábra mutatja be szemléletesen:
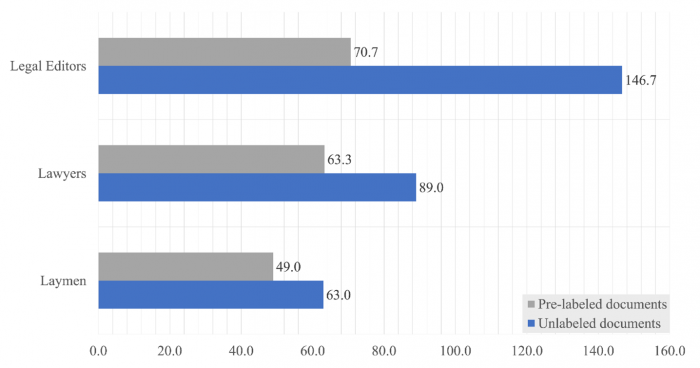
Az egyes csoportok (a szerkesztők, a jogászok és a laikusok) által a 3 óra alatt átlagosan bekategorizált dokumentumok száma, címkézetlen vagy előre felcímkézett dokumentumok esetén
Ezek alapján az eredmények azon előzetes várakozásainkat tükrözik, miszerint azonos idő alatt a jogi szerkesztők azok, akik átlagosan a legtöbb dokumentumot tudják pertárgy szerint felcímkézni (átlagosan 108,7 dokumentumot, ha az előre felcímkézett és a címkézetlen dokumentumokat, vagyis a szürke és kék sávban jelölt eredményeket átlagoljuk), majdnem dupla annyit, mint a laikusok – ők ugyanis átlagban 56 dokumentumot tudtak felcímkézni a 3 óra alatt. Az eredmények emellett azt is mutatják, hogy a legfelkészültebb szakértők is csak nagyjából 300 dokumentumot lennének képesek felcímkézni egy munkanap alatt, ha úgy számolunk, hogy szünet és ebédidő nélkül egész nap ezt csinálják.
Órák vagy évek?
Ez azt jelenti, hogy ha egy jogi adatbázis-kezelő az összes nyilvánosan elérhető magyarországi bírósági határozatot be szeretné pertárgy szerint kategorizálni emberi munkával, akkor nagyjából két évnyi munkaidőt venne igénybe, ha a leginkább hozzáértő szakértőit alkalmazza erre a viszonylag alacsony hozzáadott értékű munkára. Ha laikusokat alkalmaz, akik alacsonyabb munkabért igényelnének, akkor körülbelül négy és fél évnek megfelelő munkaidőre lenne szükség. Ráadásul itt még a címkézés pontossága és hatékonysága nincs is figyelembe véve. Ha ugyanis a jogi adatbázis készítője megbízható pontosságú címkéket szeretne előállítani, akkor neki – ahogy azt később látni fogjuk – legalább három független kategorizálóra van szüksége, akik ellenőrzik egymás munkáját, ami így a fenti munkaidőket és az ezzel járó költségeket megtriplázza. Viszont cserébe a címkék is kétszer pontosabbak és megbízhatóbbak lesznek. Ezzel szemben a gépi tanuláson alapuló automatikus kategorizáló algoritmusnak a 220 dokumentum felcímkézése percekbe, a teljes 170.000 adatállományé pedig néhány órába telne.
Egy másik meglepő eredmény viszont, ami kijött a kutatás adataiból, és amire előzetesen nem számítottunk, hogy a dokumentumok előzetes felcímkézése belassítja a kategorizálási munkafolyamatot. Azok a résztvevők ugyanis, akik előzetesen felcímkézett dokumentumokat kaptak, kevesebb dokumentumot címkéztek fel (átlagosan 61 darab dokumentumot három óra alatt), mint azok, akik gépi címke nélküli dokumentumot kaptak (99,5 dokumentum átlagban). Az is igaz viszont – ahogy azt később látni fogjuk –, hogy ezek a résztvevők ugyanannyi dokumentumból majdnem 50%-kal több információt nyertek ki, mint azok, akik címkézetlen dokumentumokat kaptak kategorizálásra. Ezek szerint azok, akik előzetesen felcímkézett dokumentumot kapnak, sokkal részletesebben olvassák el az adott dokumentumot, hogy az a címke valóban helyes-e.
Pontosság
Ezt követően pedig azokra a kérdésekre kerestük a választ, hogy mennyi információt képesek kinyerni a dokumentumokból az egyes kategorizálók, hogy megbízhatóbb, pontosabb-e az algoritmus az emberi kategorizálóknál, valamint, hogy mennyire képes elfedni a gépi kategorizáló segítség a résztvevők kompetenciájában rejlő különbségeket a jogi dokumentumok kategorizálása során. Ahogy a módszertant bemutató cikkben is említettük, több modellt is használtunk az eredmények elemzésére és összehasonlítására. Mindenekelőtt a különböző résztvevők címkézésének pontosságát mértük meg. A címkézés lehetett részben vagy egészében pontos. A részbeni pontosság azt jelenti, hogy legalább egy helyes címkét ráraktak az adott határozatra a potenciálisan helyesek közül. Fontos, hogy a pontosságot minden esetben annyi dokumentumra néztük, ameddig az adott kitöltő eljutott a kategorizálás során három óra alatt, nem pedig a teljes adathalmazra. Így a következő ábra azt mutatja meg, hogy az egyes résztvevő csoportoknál átlagosan mekkora volt azoknak a dokumentumoknak az aránya, ahol legalább egy darab jó címkét találtak:
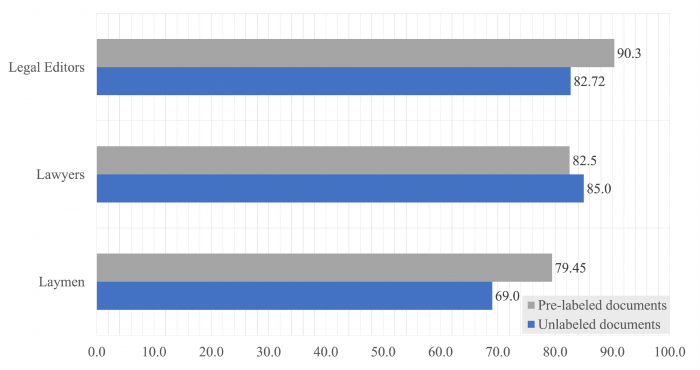
Az egyes résztvevő csoportok mekkora százalékban találtak meg legalább egy jó címkét az általuk bekategorizált dokumentumokból
Ezek alapján látható, hogy még a laikusok is képesek voltak átlagosan a címkézetlen dokumentumok 69%-ának esetében legalább egy jó címkét találni. Ráadásul azoknak a laikusoknak a munkája, akik előre felcímkézett dokumentummal dolgoztak majdnem képes volt elérni a címkézetlen dokumentummal dolgozó szerkesztők címkézésének pontosságát. Ebben a tekintetben tehát úgy tűnik, hogy a gépi tanuláson alapuló algoritmus segítsége képes részben elfedni a kompetenciabeli különbségeket.
Azonban más képet kapunk, ha a címkézés pontosságát azoknál a dokumentumoknál nézzünk, amelyek legalább 3 címke alá is beleillenek. Ezeknél azokat a címkézéseket fogadtuk el helyesnek a résztvevőktől, ahol legalább 3 jó címkét megtaláltak. A következő ábrán látszik, hogy azok, akik a gép által előre felcímkézett dokumentumot kapták, jelentősen jobb eredményeket értek el, mint azok, akik címkézetlen dokumentumokat kaptak:
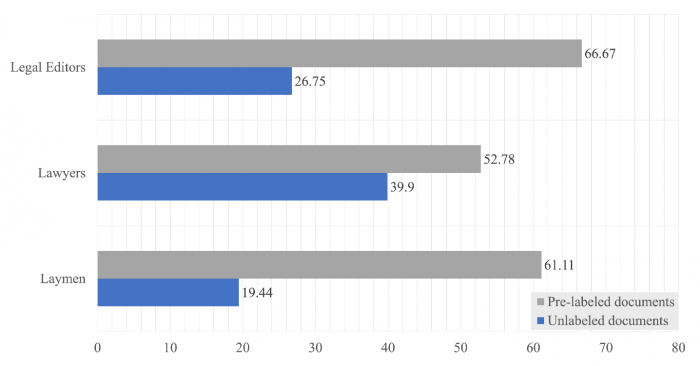
Az egyes résztvevő csoportok a kategorizálás során mekkora arányban találtak meg legalább 3 jó címkét azok között a dokumentumok között, amik legalább 3 címke alá besorolhatóak
Itt is látszik továbbá, hogyha mindkét csoport előre felcímkézett dokumentumot kap a címke helyességének ellenőrzésére, akkor nincs jelentős különbség a laikus és a jogi szakértő munkája között. Ez azt jelenti, hogy az algoritmus használata egyrészt képes akár 50%-kal is megnövelni a kategorizálás pontosságát bizonyos esetekben, másrészt képes elfedni a kompetencia különbségeket.
Teljesítmény
Végül pedig összehasonlítottuk a legjobban teljesítő csoport, tehát a jogi szerkesztők, valamint a gépi tanuláson alapuló algoritmus kategorizálási teljesítményét a módszertant taglaló cikkünkben bemutatott pontrendszer alapján. Ahogy a következő ábrán is látszik, a gép 488 pontot ért el a potenciális 1020 pontból, ami viszonylag rossz teljesítménynek mondható, viszont azt is láthatjuk, hogy a szerkesztőkkel összehasonlítva átlagosan majdnem 50%-kal jobb eredményt ért el, mint a legkompetensebb szerkesztők három óra alatt:
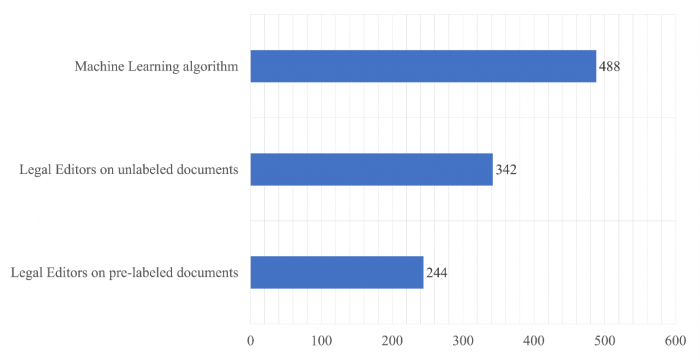
Az előző cikkben bemutatott pontrendszer alapján a gépi tanulás alapú algoritmus, valamint a szerkesztők két csoportja (címkézetlen vagy előre felcímkézett dokumentumokat kapott) mennyi információt tudott kinyerni a teljes adathalmazból a 3 óra alatt
Az ábrán látható másik érdekes eredmény, hogy azok a szerkesztők, akik gépi segítséget használtak, összesen majdnem 40%-kal kevesebb információt nyertek ki a felcímkézett dokumentumhalmazból, mint azok, akik címkézetlen dokumentumokon dolgoztak. Viszont ha azt nézzük, hogy egy dokumentumból átlagosan mennyi információt sikerült kinyerniük a résztvevőknek, akkor azt látjuk, hogy azok, akik előre felcímkézett dokumentumokat ellenőriztek, jelentősen jobb eredményeket értek el, mint azok, akik gépi segítség nélkül dolgoztak. Ez is azt mutatja, hogy ugyan az algoritmus segítsége lassabbá teszi a munkát, ám ezáltal alaposabb és hatékonyabb is lesz a munkavégzés. Ezek mellett a következő ábra azt is megmutatja, hogy az algoritmus teljesítménye egy dokumentumra nézve megközelíti azoknak a jogi szerkesztőknek a munkáját, akik gép segítség nélkül dolgoznak:
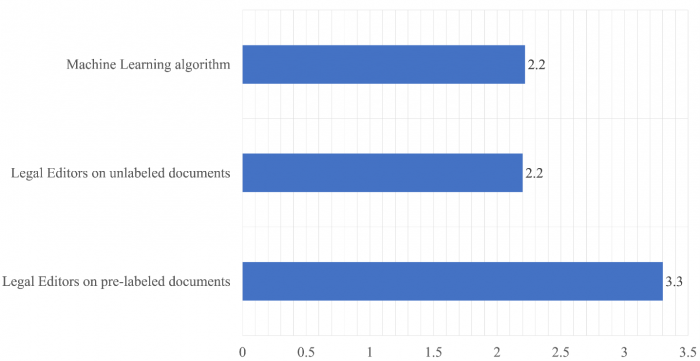
A pontrendszer alapján az algoritmus, valamint a szerkesztők két csoportja által átlagosan egy dokumentumból kinyert információ
A legjobban teljesítő szerkesztő eredménye a gép ellen
Végül pedig azt néztük meg, hogy hogyan alakult átlagosan azoknak a szerkesztőknek a teljesítménye, akik gépi segítség nélkül dolgoztak, valamint a legjobban teljesítő szerkesztőnek az idő múlásával a géphez hasonlítva:
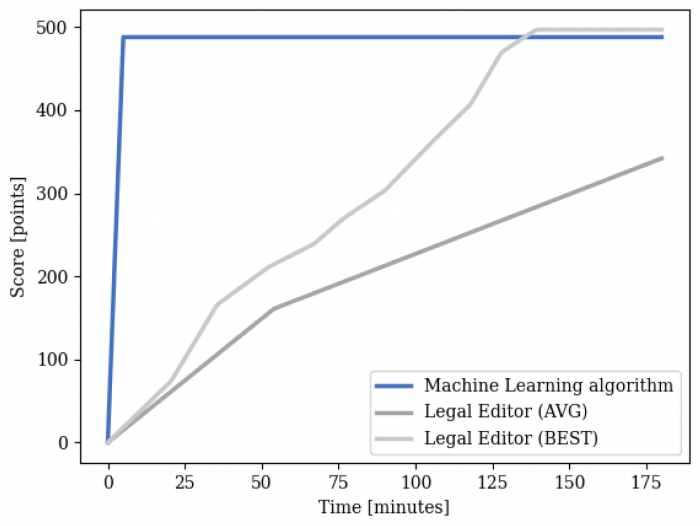
Az ábra azt mutatja meg, hogy az idő múlásával mennyi pontot szereztek a szerkesztők átlagosan, a legjobban teljesítő szerkesztő, valamint az algoritmus a kategorizálás során a pontrendszer alapján
Ez azt mutatja, hogy még a legjobban dolgozó szerkesztő is csak több, mint két óra után tudta elérni az algoritmusnak a teljesítményét, és még ő is csak 3 ponttal szerzett többet, mint a gépi tanuláson alapuló algoritmus. Ráadásul látszik, hogy mind átlagban a szerkesztőknél, mind pedig a legjobban teljesítő szerkesztő esetében egy ponton láthatóvá válik egy töréspont, ami után csökken a teljesítőképességük, ami egyértelműen a fáradás jele egy ilyen monoton munkavégzésnél. Ezek alapján mondható, hogy a gépi tanuláson alapuló algoritmusokat több módon is lehet használni jogi feladatok elvégzésére vagy támogatására. Egyrészt felválthatja a jogi szerkesztők ilyen jellegű munkafolyamatait, másrészt javíthatja is azoknak a teljesítményét.
A cikksorozat negyedik, utolsó részében bemutatjuk a további eredményeket, valamint ismertetjük a konklúziókat, amiket a kutatásból le tudtunk vonni.


Akiket pedig részletesebben is érdekelnek a kutatás eredményei és a megállapításaink, megtalálhatja a kutatásból készült teljes, angol nyelvű tanulmányunkat itt.
A tanulmány szerzői:
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője
- Üveges István, a Szegedi Tudományegyetem Nyelvtudományi Doktori Iskolájának doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója
- Orosz Tamás PhD, szoftverfejlesztő mérnök
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője