Amikor a mesterséges intelligencia megmérgezi magát: a beazonosíthatatlan szintetikus adatok problémája
A generatív mesterséges intelligencia terjedése maga után vonta a nem ember által létrehozott képek, szövegek videók rohamos elszaporodását is. Egyes új kutatások arra utalnak, hogy az ilyen „szintetikus adatok felhasználása új GAI (Generative artificial intelligence, azaz generatív mesterséges intelligencia) modellek tanítása során katasztrofális következményekkel járhat. Ez még inkább sürgetővé teszi a mesterségesen generált tartalmak explicit jelölésének kötelezettségét, amennyiben a jövőben továbbra is profitálni szeretnénk az MI nyújtotta gazdasági és társadalmi előnyökből.
A gépi tanulás világában már viszonylag régóta elterjedt gyakorlat, hogy egyes modellek betanításához nem pusztán eredeti adatokat alkalmaznak, hanem némely esetben mesterségesen generáltakat is. A múltban ez leginkább olyankor volt hasznos, amikor nem állt rendelkezésre elegendő mennyiségű valós adat egy probléma megoldásához.
Ilyen tipikus eset, amikor egy gépi tanulási rendszer valamilyen osztályozási feladatot old meg. A konkrét feladat lehet például az, hogy orvosi diagnosztikai célokra fejlesszünk olyan alkalmazást, amely anyajegyeket ábrázoló képeket osztályoz aszerint, hogy azokon található-e valamilyen rákra utaló elváltozás vagy sem. Ez voltaképpen egy bináris osztályozás, amelynek során igen/nem címkével kell ellátnunk a beérkező új képeket aszerint, hogy azok igényelnek-e bővebb kivizsgálást. A probléma megoldása során felmerülhet, hogy nem rendelkezünk elegendő, kézzel címkézett képpel a modell betanításához. Hasonlóképpen az is gondot okozhat, ha szinte csak olyan képeink állnak rendelkezésre, amelyek egészséges anyajegyeket ábrázolnak. Az első esetben a modell nem lát elegendő példát ahhoz, hogy hatékonyan tudjon általánosítani a feladat megoldása során, ezért az általa hozott döntések nem lesznek kellőképp megbízhatóak. A második esetben, mivel a tanítóadatok között erős túlsúlyban voltak a problémamentes bőrfelületet ábrázoló képek, a modell jó eséllyel nem ismeri majd fel a problémás eseteket. Ez utóbbi forgatókönyvet szokás a tanítóadatok „kiegyensúlyozatlan eloszlásából” eredő hibának is nevezni.
Az adat augmentálás olyan eljárások gyűjteménye, amelynek során a modell tanításakor jelentkező adathiányt kíséreljük meg orvosolni új, mesterségesen generált adatok létrehozásával. A generált adatok keletkezhetnek valós adatok módosítása útján (augmented data) vagy teljesen új adatok létrehozásával is (synthetic data).
A fenti példánál maradva, ha egy képet tükrözünk, esetleg irreleváns részleteket eltávolítunk róla, akkor augmentált adatot kapunk, amely növelheti a modell teljesítményét és robosztusságát. Ha egy nagy nyelvi modellt (LLM) használunk szöveggenerálásra, akkor szintetikus adatot kapunk, amelyet szintén használhatunk a meglévő eredeti adathalmazunk „feldúsítására”. Ez utóbbit az különbözteti meg az augmentált adattól, hogy nincs valódi értelemben vett eredetije, nem tudjuk visszavezetni egy konkrét, valós adatra, amelyből keletkezett.
A mesterséges adatokkal való munkának már korábban is ismert volt egy érdekes tulajdonsága. Korábbi kísérletek során többen is vizsgáltak olyan forgatókönyveket, amelyekben az augmentált / szintetikus adatok „értékére” voltak kíváncsiak. Több elemzés is készül arról, hogy azonos mennyiségű csak eredeti adat, eredeti és mesterségesen generált adat, illetve csak mesterségesen generált adat felhasználása mellett ugyanazon modellek milyen teljesítményt képesek elérni. Gyakori tapasztalat volt, hogy a pusztán mesterséges adatokkal tanított modellek teljesítménye minden esetben elmaradt az azonos mennyiségű eredeti adattal tanított modellekétől. Más szavakkal, a mesterséges adatok, ha eredetikkel együtt alkalmazzuk őket, segíthetnek a modellnek jobb teljesítményt elérni, azonban az eredeti adatok minden esetben jobb minőségű eredményekhez vezetnek.
A köztudatba csak az elmúlt másfél évben berobbant generatív modelleket, mint amilyen például az OpenAI szöveggeneráláshoz használható GPT-3, 3.5, vagy 4 -es modellje, a képgeneráláshoz használható DALL-E 2, 3, a Midjourney vagy akár az Adobe Firefly modellje során hatalmas mennyiségű tanítóadatra volt szükség. Ezek az adatok legkönnyebben az interneten érhetőek el, a begyűjtésük pedig automatizáltan, egy web srcaping-nek nevezett folyamattal történik.

Az elmúlt évekig valójában nem álltak rendelkezésre olyan minőségű generatív modellek, amelyek képesek lettek volna elfogadható minőségű szintetikus adatot előállítani. A helyzet azonban a közelmúltban megváltozott, és ezek a szintetikus adatok egyre nagyobb mennyiségben vannak jelen a világhálón is. Ezzel önmagában még nem lenne semmi probléma, hiszen számos példát láthatunk a képgenerátorok lenyűgöző teljesítményére csakúgy, mint arra, hogy a szöveggenerálás mennyire hasznos eszköz lehet mind a fejlesztők, mind az átlagember kezében.
A problémát valójában az jelenti, hogy sok esetben a szintetikus adatok nincsenek semmilyen módon megjelölve. Emiatt egy-egy adott tartalomról a készítőjén kívül sokszor senki sem tudja biztosan, hogy az „eredeti” (ember alkotta), vagy pedig mesterséges intelligencia készítette. A jelenlegi trendek alapján joggal feltételezhetjük, hogy a szintetikus adatok térnyerése a világhálón nemcsak, hogy lassulni nem fog, de az ilyen tartalmak terjedésénének sebességében rohamos növekedés várható. Tény, hogy például Európai Unió komoly lépéseket készül tenni annak érdekében, hogy a mesterséges intelligenciával előállított tartalmak esetében kötelező legyen jelölni ezt a tényt (például a dezinformáció elleni harc érdekében). Azonban, még ha ez maradéktalanul meg is valósul, egy átfogó, a világ egészére kiterjedő szabályozás a közeljövőben nem valószínű. Enélkül pedig a mesterségesen generált tartalmak továbbra is többé-kevésbé ellenőrizetlenül keletkeznek és kerülhetnek be a későbbi generációs generatív mesterséges intelligencia modellek tanítóadatiba.
Nemrégiben kezdtek napvilágot látni olyan kutatások, amelyek a szintetikus adatok hatását vizsgálják például nagy nyelvi modellek betanítása során. Ezek alapján úgy tűnik, hogy az a fajta homogenitás, amit az emberi kreativitás hiánya okoz már rövidtávon is katasztrofális hatással van a generatív modellek teljesítményére.
A kísérletek keretében kutatók azt vizsgálták, mi történik, amennyiben egy ilyen modellt kizárólag szintetikus adatok segítségével tanítanak be. A folyamatot több alkalommal is megismételték, minden esetben az előző generációk által generált adatokat felhasználva új modellek tanításához. Következtetéseik szerint az egyre későbbi modellek minden ilyen iteráció után egyre rosszabb minőségű kimeneteket produkálnak. Ez egyrészt abban nyilvánult meg, hogy minden generáció egyre inkább egymáshoz hasonló, homogén kimeneteket hozott létre adott feladat során. Másrészt minden generáció veszített a kimenet minőségéből is, képek esetén például azok egyre zajosabbak és értelmetlenebbek lettek.
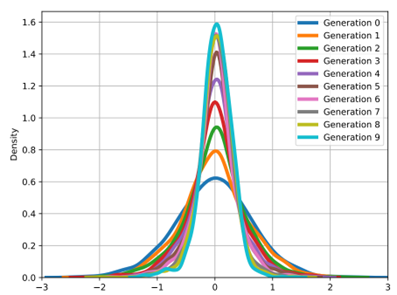
A generatív modellek kimeneteiben bekövetkező növekvő homogenitás. A szintetikus adatokon tanított modellek idővel az „átlag” felé kezdenek konvergálni, elvesztve az emberi forrásból származó adatokban jelenlevő sokszínűséget és újszerűséget. (A kép forrása innen.)
A jelenség nem csak arra mutat rá, hogy a jelenleg létező modellek rendkívül korlátozott mértékben képesek „kreatív” eredményeket produkálni friss emberi input hiányában, de előrevetíti a közeljövő talán legégetőbb problémáját is.
Ahhoz, hogy a generatív mesterséges intelligencia ne kezdje el „megmérgezni” saját magát a jelöletlen, szintetikus adatokkal, azokat valahogyan szűrhetővé kell tenni. Ez nem pusztán jogi, de a fentiek alapján megkerülhetetlen technológiai kérdés is. Emellett felmerül a dilemma, hogy a nagy technológiai óriások, akik jelenleg a GAI fejlesztéseket uralják, hogyan reagálnak majd a problémára. Figyelembevéve az egyre nagyobb modellekhez szükséges egyre hatalmasabb adatigényt, könnyen elképzelhetők olyan praktikák is, amelyek során a felhasználókat manipulatív eszközökkel veszik rá új adatok létrehozására.
A kialakulóban lévő helyzetet hasonlították már ahhoz is, amely a 20. században a Geiger számlálók kapcsán merült fel. A században lefolytatott nukleáris kísérletek, illetve az ezeket kísérő radioaktív kihullás nyomán sugárzó anyagok jutottak a Föld légkörébe. Ez megzavarta a műszerek működését, hiszen a számlálóban alkalmazott fém kis mértékben maga is sugárzott. Válaszképpen megkezdődött olyan, jellemzően világháború előtti roncsok felkutatása, amelyek még az atomkísérletek ideje előtt legyártott fémeket tartalmaztak, ezért pedig mentesek voltak az efféle sugárszennyezettségtől.
Az AI világában is könnyen bekövetkezhet egy hasonló helyzet, amikor is a GAI megjelenése és elterjedése előtt keletkezett adatok lesznek a legértékesebb források az új modellek elkészítése során.
Noha a generatív mesterséges intelligencia fejlődését megállítani képes szintetikus adatok terjedése már napjainkban is jelen van, a helyzet egyelőre fenntartható. A közeljövőben azonban ahhoz, hogy a technológiai fejlődés jelenlegi ütemét tartani tudjuk, elengedhetetlennek látszik a szintetikus adatok egyértelmű jelölése. A kérdés technológiai vonatkozásai mellett ez fontos szempont például a dezinformáció, a választási manipulációk, vagy éppen az adatvédelemmel kapcsolatos visszaélések megelőzése érdekében is. Habár mutatkoznak jelei hasonló jogalkotási trendeknek (például az EU esetében), egyelőre nyitott kérdés a hasonló jogszabályok globális elterjedése, és azok betartatásának pontos mikéntje is.
A cikk szerzője Üveges István, a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője, valamint a HUN-REN Társadalomtudományi Kutatóközpont projektkutatója.
A cikk angolul When AI Poisons Itself; the Problem of Unidentifiable, Artificially Generated Data címmel a Constitutional Discourse oldalán jelent meg.