Gépi tanulás kevés adat segítségével: Meta-learning és Few-shot Learning az adózási joggyakorlat dokumentumain II.
Cikksorozatunk második részében bemutatjuk, hogy milyen eredményei és konklúziója lett a Meta-learningen alapuló gyakorlati kísérletnek, melynek alapját adózási joggyakorlaton alapuló dokumentumok képezték.
Az elmúlt másfél évben elterjedt nagy nyelvi modellekre épülő megoldások, mint például a ChatGPT, legfőbb pozitív tulajdonsága, hogy viszonylag egyszerűen képesek adaptálódni különböző feladatokra, és már pár példa megmutatásával képesek akár komplex feladatokat is ellátni. Ezeknek a megoldásoknak ez az előnye alapvetően a modelleknek a Meta-learning és Few-shot Learning tulajdonságából fakad. A nagy nyelvi modelleknek viszont megvan az a hátránya, hogy meglehetősen erőforrásigényesek, így saját eszközön nehéz futtatni őket, a külső szerveren való futtatása pedig adatvédelmi aggályokat vethet fel, és az olyan területeken, mint például a jogi munkavégzés sok esetben még belső szabályzatokba is ütközik a használatuk. A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. ezért egy közös kutatásban azzal kísérletezett, hogy a korábbi mesterséges intelligencia megoldások és a kisebb nyelvi modellek Few-shot Learning képessége mire képes összehasonlítva más megoldásokkal.
A cikksorozat első részében bemutattuk, hogy mit is jelent pontosan a Meta-learning és a Few-shot Learning, melyek a hagyományos gépi tanulási megoldások hátrányai, és a Few-shot Learning hogyan képes ezeket kiküszöbölni. A cikksorozat második, egyben befejező részében pedig bemutatjuk, hogy hogyan is épült fel az a Few-shot architektúra, vagyis az a rendszer, amit használtunk, és ez hogyan teljesített az adózási dokumentumokon.
A Few-shot Learning architektúra felépítése
Ahogy a cikksorozat előző részében is bemutattuk, a Few-shot Learning lényege, hogy akkor is lehessen hatékony mesterséges intelligencia modelleket fejleszteni, ha csak kevés tanítóadat áll rendelkezésre, és nincs mód tanítóadatok gyártására, vagy csak nagyon erőforrásigényesen, vagy esetleg az alkalmazandó kategóriahalmaz túlságosan rugalmas, és mire egy kategóriára megfelelő mennyiségű tanítóadat állt elő, már született egy újabb kategória és lehetne a munkát elölről kezdeni. Ez a megközelítés az, ami képes kiküszöbölni az olyan hagyományos gépi tanulási megközelítések hátrányait, ahol jellemzően fix kategóriarendszerre, illetve minden egyes kategóriához megfelelő mennyiségű és jó minőségű tanítóadatra van szükség.
Ez a képesség az, ami többek között az olyan generatív mesterséges intelligencia eszközöket, mint a ChatGPT népszerűvé tette, mert csupán pár példa megmutatásával már komplex feladatokat is el lehet végeztetni vele. A ChatGPT-hez hasonló nagy nyelvi modellre épülő megoldások azonban meglehetősen erőforrás igényesek, és így használatuk limitált lehet. Ezért érdemes megvizsgálni a korábbi modellek és a korábbi megoldások Few-shot Learning képességeit.
Egy hagyományos Few-shot Learning architektúra összeállításánál két fontosabb szempontot lehetséges figyelembe venni: annak a hálónak a felépítését, aminek a segítségével a vektortérben leképezzük az adott dokumentumokat és így megpróbáljuk megtalálni az jelentéstanilag és téma szempontjából egymáshoz közel állókat, valamint azt, ahogyan feltanítjuk ezt a hálót. Egy Few-shot Learning feladatra többnyire sziámi hálókat (ld. előző cikk) szoktak használni, ami a neurális háló egy speciális típusa, és külön a kis adathalmazokon való tanítás hatékonnyá tételére hozták létre. Több sziámi háló struktúra elképzelhető, mi a kutatás során kettőt próbáltunk ki:
- az első architektúra egy Dense hálót tartalmazott, aminél a BERT modell mondatokra vonatkozó átlagos vektorait használtuk fel;
- a másik esetben pedig a Dense háló mellett egy kétirányú LSTM hálót is használtunk, illetve ez a BERT modell statikus szórész-beágyazásait használta fel.
Most anélkül, hogy belemennénk ezek technikai részleteibe, a két sziámi háló struktúra között az a különbség, hogy az egyik az egyes szavak információit kapta meg, míg a másik csak mondatokra vonatkozó átlagos információkat kapott. Emellett a második egy LSTM, vagyis Long Short-Term Memory hálót is tartalmazott, aminek a lényege, hogy ez a háló képes adatsorokon átívelően tanulni, és hasonlóságokat észrevenni. A szavakat adategységekként értelmezve ez a modell alkalmas tehát a szavak közti összefüggések megtanulására, és így az adott szövegről értelmes vektorreprezentáció biztosítására.
A másik fontos dolog egy Few-shot Learning feladatnál a számi háló feltanítása. Az egyik bevett technika a triplet loss-os tanítás, aminek a lényege, hogy a klasszikus gépi tanuláshoz képest, ahol egy adatot, annak bemeneti és kimeneti változóját használjuk a tanításhoz, itt 3 különböző elemet választunk ki a háló felépítéséhez. Az első az úgynevezett anchor (horgony), egy véletlenszerűen kiválasztott elem az adathalmazból. A második egy pozitív, ugyanúgy az anchor kategóriájához tartozó másik elem, a harmadik pedig egy negatív, egy véletlenszerűen kiválasztott másik kategóriához tartozó elem. A sziámi háló olyan transzformációt tanul meg, amelynél az anchor és a pozitív minták távolsága kisebb, mint az anchor és a negatív mintáé. Ezekkel az adattriókkal pedig ki tudunk alakítani egy struktúrát, ami aztán képes az új adatokat megfelelően klasszifikálni úgy, hogy kevesebb adatot használunk fel, mint egy hagyományos gépi tanulási projekt esetén.
Az általános triplet loss-os adatkiválasztáson azonban nekünk finomítani kellett a kutatáshoz felhasznált dokumentumok természete miatt. A kutatáshoz ugyanis a Wolters Kluwer Hungary Kft. Jogtár rendszerében lévő Adózási joggyakorlathoz tartozó dokumentumokat használtuk, ezeknek a dokumentumoknak a természete pedig olyan, hogy egy-egy dokumentum akár több kategóriába is beletartozhat. Ezért figyelnünk kellett arra, hogy amennyiben az anchor dokumentum több kategóriához is tartozik, a negatív halmazból kiválasztott dokumentum olyan legyen, ami biztosan egyik kategóriáját sem tartalmazza, máskülönben összezavarhatjuk a modell működését.
A sziámi architektúrák feltanítását követően pedig összehasonlítottuk, hogy az egyes megoldások hogyan teljesítenek egymáshoz képest, valamint, hogy a legjobb Few-shot Learning megoldás hogyan teljesít a hagyományos gépi tanulási technikákkal összehasonlítva.

Eredmények
Mindenekelőtt azt akartuk összehasonlítani, hogy a két különböző Few-shot Learning sziámi háló struktúra közül melyik teljesít a legjobban, melyik az, amelyiket érdemes összehasonlítani a hagyományos gépi tanulási megoldásokkal. Ehhez 409 darab Adózási joggyakorlathoz tartozó dokumentumot a Wolters Kluwer Hungary Kft. jogi szerkesztő munkatársai kézzel felcímkéztek, hogy össze tudjuk hasonlítani azokkal a címkékkel, amiket az algoritmusok adnak a dokumentumokra. Emellett arra is kíváncsiak voltunk azon túl, hogy a két architektúra közül melyik teljesít a legjobban, hogy hogyan alakul a sziámi háló alapú klasszifikálók működése az alapján, hogy hány darab klasszifikáláshoz használt mintaadatot adunk nekik a működés során. Ezért összehasonlítottuk, hogyan teljesítenek a modellek, ha 1, 2, 5, 10, 20 vagy 50 dokumentumot adunk nekik kategóriákként mintaadatként.
A Few-shot Learning megoldásoknak ugyanis az a lényege, hogy sokkal kevesebb tanítóadat használata elég egy hatékony algoritmus felépítéséhez, mint a hagyományosabb gép tanulási technikák esetén. Az osztályozás során a sziámi háló által megtanult leképezést használjuk fel a mintaadatok vektorainak meghatározására, és egy új dokumentum abba az osztályba fog bekerülni, amelyik kategória vektorához képest a vektora a legközelebb van. Amennyiben egy dokumentumra több címke is illeszthető, úgy egyéb megfontolások is szükségesek, hiszen ha mindig csak a legközelebbi kategória címkéjét adjuk a dokumentumainkra, akkor mindenhol csak egy címke lesz, ami nem feltétlenül elégséges. Tudnunk kell tehát becsülni, hogy egy adott dokumentumra hány címkét kell adnunk. Ennek megoldása lehetséges egy újabb neurális háló feltanításával, esetünkben azonban egyszerűen annyi legközelebbi adatot választottunk ki, ahány címke szerepelt a jó dokumentumban. Az alábbi ábrán látszódik, hogy a BERT mondatátlagokat és egyszerű Dense hálót használó, valamint a BERT szórész-beágyazásokat és LSTM hálót is használó architektúrák milyen eredményeket értek el a 409 darab dokumentum kategorizálása esetén. Baseline összehasonlításként beraktuk azt is, hogy a sziámi hálót nem használó egyszerű BERT és BERT CLS modellek hogyan teljesítenek ezen a feladaton. A vízszintes tengelyen jeleztük logaritmikus skálán, hogy hány tanítóadatot használtunk az egyes kategóriákhoz, és eszerint hogyan alakult a modellek teljesítménye. A függőleges skálán látszódik az egyes modellek hatékonysága a Micro F1 metrika alapján számolva. A Micro F1 metrika egy olyan mérőszám, ami egy ilyen gépi tanulási feladat két fontos aspektusát képes egyesíteni, a pontosságot és a fedést, a különböző kategóriákat egy egységként kezelve. Az ábrán látszódik, hogy a két típusú architektúra közül a BERT átlagmondatokat és a sima Dense hálót alkalmazó sziámi háló megoldás tudott kiemelkedő eredményeket elérni. Az is látszik, hogy már kategóriánként 5 darab mintaadat használatával képes hatékony eredményt elérni.
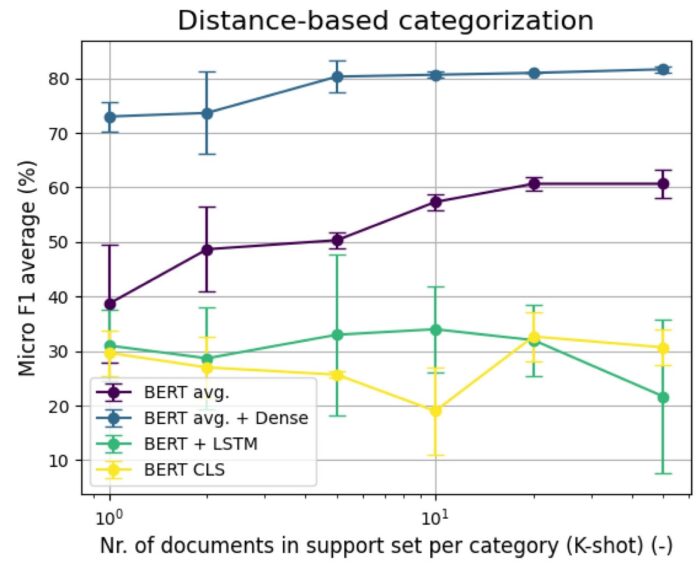
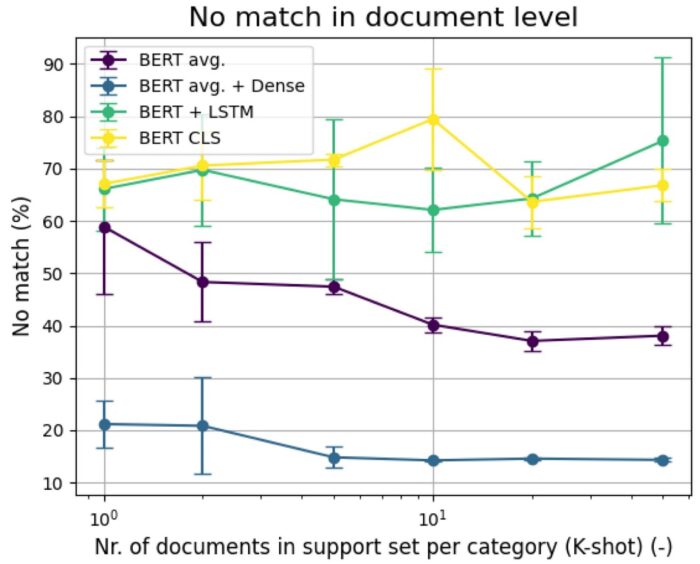
Talán még jobban kijön ez az eredmény és a különbség a modellek működése között, ha fordítva nézzük meg az eredményeket, tehát azt vizsgáljuk meg, hogy a 409 dokumentum esetében hány százalék volt olyan, ahol a különböző modellek egy jó címkét sem találtak el, tehát teljesen rosszul működtek. Itt természetesen az a jó, ha minél kevesebb százalékon, tehát minél lejjebb vannak az ábrán az egyes modellek. Látható, hogy ebben a tekintetben is kiemelkedően jól teljesített a BERT átlagmondatokat és a sima Dense hálót alkalmazó sziámi háló.
Végül pedig megvizsgáltuk, hogy a legjobban teljesítő Few-shot Learning megoldás, tehát az egyszerű Dense hálót és a BERT mondatátlagokat használó sziámi háló hogyan teljesít a hagyományos gépi tanulási megoldásokkal szemben. Ehhez egy Transfer learning alapú megoldást választottunk. A Transfer learning a gépi tanulási megoldásoknak az a fajtája, amelynek lényege, hogy amennyiben már adott egy modell, ami képes egy adott feladat elvégzésére (pl. képes különböző állatokat felismerni), hatékonyabban, kevesebb adattal tanítható fel egy másik hasonló feladat elvégzésére (pl. megmondani, hogy egy adott állat varánusz-e vagy sem.)
Esetünkben egy adott, tágabb kategóriarendszerre létezik egy modellünk, ami az automatikus besorolását elvégzi az adatoknak. Ennek a modellnek új típusú dokumentumokat mutatva finomítani tudjuk a modellt, hogy ugyanabba a kategóriarendszerbe vagy annak egy részébe csoportosítani tudja az új típusú dokumentumokat. Így a modell fel tudja használni a tudását, amit a korábbi adathalmazon szerzett és azt is, amit az újon.
Ehhez rendelkezésünkre állt egy TF-IDF és logistic regression alapú modell, ami alapvetően 175 000 anonimizált bírósági határozaton tanult. Ennek egy részét, az adózási dokumentumok esetében releváns kategóriákra fel tudtuk használni. A felhasználáshoz tovább tanítottuk az alapmodellt 675 db Adózási joggyakorlathoz tartozó dokumentumon. Így előállt egy modell, aminek volt egy alap tudása az adózási témakörről más dokumentumok esetében, ami nagy elemszámon tanult, és kisebb elemszámon, de megkapta azt a tudást, hogy az új dokumentumtípus miben más, mint a korábbi, amin tanult.
Az alábbi, cikkből származó táblázaton látszik, hogy milyen eredményt volt képes elérni a Few-shot Learning megoldás a hagyományos gépi tanulási modellhez képest. A táblázatban Classical elnevezéssel szereplő modell az előbb bemutatott Transfer learning alapú modell, míg a Few-shot a legjobban teljesítő sziámi hálós modell. A táblázaton is látszik, hogy a Few-shot Learningen alapuló modell az Accounting ügyek címkézésén és a Complete Match kivételével, tehát, amikor az adott dokumentumra minden egyes címke helyesen került fel, nem tudta elérni a hagyományos gépi tanulási modell eredményességét. Az Accounting (számvitel) ügyek címkézése azért került külön kiemelésre, mert az az eredeti, bírósági határozatokon használt kategóriarendszerben nem volt elérhető, ezért azt a Transfer learning modell is először látta. És ugyan a Few-shot modell a többi metrika esetén nem tudta elérni a klasszikus Transfer learning alapú modell eredményességét, de azért az látszik, hogy nem sokban marad el mellette, illetve azt érdemes kiemelni, hogy a Transfer learning alapú modell összesen 175 000 + 675 db dokumentumot látott, míg a legjobban teljesítő Few-shot modell 50-50 darab dokumentumot mind a 11 kategóriából, tehát összesen 550 dokumentumot, és így volt képes ezeket az eredményeket elérni.

Összefoglalás
A sziámi háló alapú Few-shot Learning megoldásokat alapvetően nem multi-label esetekre találták ki, tehát amikor egy dokumentum esetében több releváns kategória is elképzelhető. Ennek ellenére az eredmények azt mutatják, hogy ugyan figyelni kell a tanítás során az adatok mintavételezésére, tehát nem szabad azt megengedni, hogy az anchor dokumentumhoz képest olyan dokumentum legyen a negatív adathalmazban, ami tartalmazza az anchor dokumentum valamelyik címkéjét, de ez az eljárás hatékonyan alkalmazható dokumentumok klasszifikálására, amennyiben megbecsülhető, hogy egy dokumentumra hány címke illeszthető. Megmértük, hogy az Adózási joggyakorlat dokumentumok esetében a Few-shot Learning megoldások közül a BERT mondatátlagokat használó, egyszerű Dense hálót tartalmazó sziámi modell teljesített a legjobban, illetve nem maradt el jelentősen a hagyományos Transfer learning modell eredményeitől, bizonyos metrikák esetében pedig meg is haladta azt.
A Few-shot Learningnek az a legnagyobb előnye, hogy segítségével sokkal kevesebb dokumentum felhasználásával is lehet eredményes modelleket létrehozni. Ez az előny itt is megmutatkozott, hogy egy ilyen feladat elvégzésére, hogy adójogi szakterülethez tartozó jogi dokumentumokat klasszifikáljunk mesterséges intelligencia segítségével, a több százezer dokumentum helyett pár száz dokumentum felhasználásával is lehet a hagyományos megoldásoktól nem sokkal rosszabb hatékonyságú megoldásokat készíteni. Ez pedig egy ilyen fejlesztés idő- és erőforrásráfordítását nagyban csökkentheti.
A Few-shot Learning ráadásul a most népszerű nagy nyelvi modellekre épülő generatív mesterséges intelligencia eszközök egyik legtöbbet emlegetett előnye. Az ilyen mesterséges intelligencia megoldások viszont nagy erőforrásigényűek, és a legjobban működő fajtáik, mint a GPT vagy a Cohere, többnyire zártak, tehát nem szabadon, csak felhasználási díj fizetése esetén egy külső kapcsolaton keresztül érhetőek el. Ezek a faktorok pedig nagyon sok adatvédelmi, szerzői jogi, fenntarthatósági és kitettségi problémát vetnek fel. A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közös kutatása és a fent bemutatott eredmények azonban arra világítanak rá, hogy kisebb, szabadon hozzáférhető gépi tanulási modellek Few-shot Learning képességét is érdemes kihasználni annak érdekében, hogy a fenti problémák kiküszöbölhetőek legyenek, és saját modellek segítségével bizonyos részfeladatok algoritmizálhatóak legyenek.
A kutatásról készült teljes, angol nyelvű tanulmány letölthető innen.


A tanulmány szerzői:
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője;
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője;
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója,
- Fülöp Anna, a Wolters Kluwer Hungary Kft. szerkesztőségi főmunkatársa;
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője;
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója;
- Üveges István, a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője, valamint a HUN-REN Társadalomtudományi Kutatóközpont projektkutatója.