Gépi tanulás kevés adathalmaz segítségével: Meta-learning és Few-shot Learning az adózási joggyakorlat dokumentumain I.
Hogyan is működik a Meta-learning, és milyen előnyökkel jár a hagyományos gépi tanulási modellekkel szemben? Cikksorozatunkban bemutatjuk egy Meta-learningen alapuló gyakorlati kísérleten keresztül, melynek alapját adózási joggyakorlaton alapuló dokumentumok képezték.
Az elmúlt évben elterjedt olyan nagy nyelvi modellekre épülő megoldások, mint a ChatGPT legfőbb pozitív tulajdonsága, hogy viszonylag egyszerűen képesek adaptálódni különböző feladatokra, ezért ezeket a megoldásokat, a korábbi mesterséges intelligencia megoldásokkal ellentétben nem csak speciális feladatokra, hanem sokkal általánosabb körben is lehet különböző feladatok elvégzésére használni. Ezeknek a megoldásoknak ez az előnye alapvetően a modelleknek a Meta-learning és Few-shot Learning tulajdonságából fakad. A nagy nyelvi modelleknek viszont megvan az a hátránya, hogy meglehetősen erőforrásigényesek, így saját eszközön nem lehet futtatni őket, a külső szerveren való futtatása pedig adatvédelmi aggályokat vethet fel, és az olyan területeken, mint például a jogi munkavégzés sok esetben még belső szabályzatokba is ütközik a használatuk.
A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. ezért egy közös kutatásban azzal kísérletezett, hogy a korábbi mesterséges intelligencia megoldások és a kisebb nyelvi modellek Few-shot Learning képessége mire képes összehasonlítva más megoldásokkal. Ebben a cikkben bemutatjuk, hogy mit is jelent pontosan a Meta-learning és a Few-shot Learning, valamint, hogy milyen problémákat hivatottak ezek az eszközök megoldani. A cikksorozat második részében pedig bemutatjuk, hogy pontosan milyen megoldást is használtunk, valamint milyen eredményeket ért el a közös fejlesztésünk.
A hagyományos gépi tanulási megoldások hátrányai és a Meta-learning megoldások lényege
A ChatGPT 2022 végi megjelenésével és széleskörű elterjedésével nagyon sok embernek láthatóvá vált, hogy pontosan mire is képesek a különböző mesterséges intelligencia eszközök és azon belül is a különböző természetesnyelv-feldolgozó megoldások. A természetesnyelv-feldolgozó, vagy más néven Natural Language Processing (NLP) megoldások lényege, hogy a strukturálatlan szövegeket minél hatékonyabban feldolgozzák, értelmezzék, illetve akár feladattól függően új szövegeket generáljanak. Ezeket a megoldásokat már régóta széleskörűen lehetett alkalmazni akár a jogi területen is olyan feladatokra, mint például a bírósági határozatok pertárgy szerinti automatikus csoportosítása vagy akár automatikus összefoglalók generálása, az utóbbi időben pedig kiderült, hogy is tökéletesen alkalmazhatóak.
Ezeknek az NLP fejlesztéseknek a legnagyobb hátránya azonban az volt korábban, hogy a legtöbb esetben az eredményes működéshez sok adatra volt szükség a fejlesztés során. Ennek az oka alapvetően az, hogy a hagyományos NLP megoldások döntő része úgynevezett felügyelt gépi tanuláson alapszik (más néven Supervised Learning). A felügyelt tanítás lényege, hogy az algoritmus paramétereit a hatékony feladat ellátáshoz mintaadatok segítségével állítjuk be, ami azt jelenti, hogy kellő számú mintát mutatunk egy modellnek, amiről megmondjuk, hogy milyen csoportba sorolja be. Így amikor jön egy ismeretlen adat, akkor azt már nagy hatékonysággal tudja automatikusan kategorizálni a korábbi adatok szabályszerűségeit ismerve és feldolgozva. Ezeknek a megoldásoknak az volt az előnye, hogy a modellek így tényleg optimálisan rá tudtak tanulni egy adathalmaz szabályszerűségeire, és akár az adott téma szakértőinek eredményességével tudtak ellátni konkrét feladatokat.
A hátrányuk viszont az, hogy szükség van a feladat elvégzéséhez egy fix kategóriarendszerre, illetve minden egyes kategóriához megfelelő mennyiségű és jó minőségű tanítóadatra. Ez viszont sok esetben nem feltétlenül áll rögtön rendelkezésre egy ilyen típusú gépi tanulási fejlesztés esetén. Ennek kiküszöbölésére több megoldás is rendelkezésre áll. Az egyik az úgynevezett data augmentation, amikor mesterséges módon hozunk létre szintetikus adatokat az eredeti dokumentumok valamilyen megváltoztatásával. Ezzel viszont az a probléma, hogy nagyban ronthatja a modell működését, ha nem eredeti adatokat lát és nem az eredeti szabályszerűségekre képes rátanulni, ahogy azt a nagy nyelvi modellek esetében is lehetett látni. A másik megoldás, hogy emberi erővel, a szakértők munkáját és tudását felhasználva hozunk létre tanítóadatokat kézzel, például címkézéssel. Ez viszont alapvetően idő- és erőforrásigényes, a szakértőket pedig addig kiveszi a mindennapi munkavégzésből. Ráadásul vannak olyan esetek is, amikor ilyen rögzített kategóriarendszer felállítására nincs is lehetőség, mert mondjuk olyan gyorsan változnak a felismerendő kategóriák. Egy másik típusú hátrányt jelent a supervised modelleknél, hogy ezeket alapvetően csak arra a konkrét feladatra lehet használni, amire feltanították, és nem lehet általánosabban különböző feladatok elvégzésére használni.
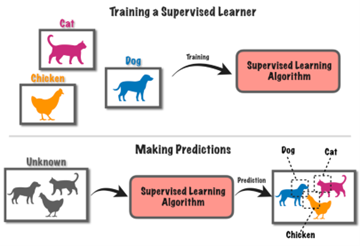
A felügyelt tanítást általánosságban bemutató ábra. A példán egy olyan algoritmust fejlesztettek, ami képes meghatározni és elkülöníteni egymástól a képeken a macskákat, a kutyákat és a csirkéket. Ehhez megfelelő mennyiségű képet mutattak az algoritmusnak macskákról, kutyákról és csirkékről, ezt követően pedig az algoritmus képes volt ezeket az állatokat felismerni egy képen. Forrás
Ezeket a hátrányokat igyekszik kiküszöbölni az úgynevezett Meta-learning megközelítés, ami az olyan nagy nyelvi modelleknek is az alapja, mint a GPT, a PaLM vagy a LLaMA. A Meta-learning lényege és kiindulópontja, hogy általában, amikor az ember valamilyen új dolgot tanul meg vagy új képességeket sajátít el, akkor többnyire nem kell nulláról kezdenie, hanem van valamilyen előzetes tudása vagy képessége, amire építhet, illetve emellett eleve rendelkezik egy bizonyos fokú képességgel új ismeretek és képességek megszerzésére. Például amikor egy gyerek lát egy négylábú, ugató, szőrös állatot, akkor elegendő csupán egy pár kutyát látnia az életében, hogy később felismerje, amikor egy kutyával találkozik. Ugyanígy ezt követően elegendő csak egy pár macskát látnia, hogy meg tudja különböztetni egymástól a kutyákat és a macskákat. Ugyanez a cél a Meta-learning esetében, vagyis hogy képessé tegyük az algoritmusokat arra, hogy megtanuljanak tanulni, tehát képesek legyenek a gépi tanulási folyamatot hatékonyabbá tenni, azzal, hogy egyrészt kevesebb mintaadatra legyen szükség a feltanításukhoz, másrészt pedig könnyebben adaptálódjanak más feladatokra, illetve más dokumentumtípusokra, ha arra van szükség. Ezt azáltal képes megtenni, hogy a Meta-learning modell képes felhasználni más korábbi modellek kimeneteleit és beállításait, ezekből a tapasztalatokból kiindulva pedig hatékonyabban tud ellátni új feladatokat.

Többek között a Meta-learning és azon belül is a Few-shot Learning az a képesség, ami a nagy nyelvi modelleket és az olyan szöveggeneráló alkalmazásokat, mint a ChatGPT, annyira népszerűvé tette, és hozzájárult a széleskörű elterjedésükhöz. Gondoljunk csak a Few-shot-promptingra, amikor úgy adunk egy parancsot a ChatGPT-nek annak felhasználói felületén, hogy az utasításba befoglalunk pár példa esetet a helyes megoldáshoz. Illetve a GPT-szerű nagy nyelvi modellek egész architektúrája arra van kitalálva, hogy a több milliárd paraméterből álló és hatalmas szövegállomány segítségével feltanított modell (úgynevezett pre-trained modell) ezt követően téma- vagy feladatspecifikus szövegekkel továbbtanítható, finomhangolható (fine-tuned modell), ezzel lehetővé téve ezeknek a modelleknek és az ilyen típusú megoldásoknak az általános használhatóságát és a könnyű adaptációs képességét, ami a mesterséges intelligencia eszközök egyik legfontosabb tulajdonsága.
A GPT-hez, a PaLM-hoz és a LLaMA-hoz hasonló nagy nyelvi modellek gyakorlati működésének azonban ezenfelül elég sok korlátja van, ami hozzájárul ahhoz, hogy bizonyos területeken a mindennapi munkavégzésben ezeknek a használata nem tud elterjedni. Ezek közül a legfontosabb, hogy az ilyen nagy nyelvi modellek működésének – ahogy azt már említettük – hatalmas az erőforrás igénye, ami azt jelenti, hogy saját számítógépen futtatni ezeket lehetetlen, és a felhőben történő futtatásnak is nagyobb költségigénye van. A legjobb képességű modellek ráadásul zártak, mint a GPT, tehát saját (pl. belső céges) környezetben nem is lehet azt futtatni. Emiatt az ilyen modelleknek való kitettség több szempontból is sérülékenységet okozhat, ami több helyzetben is ezen alkalmazások használata ellen szól. Ilyen terület például a jogi terület is, ahol az egyes ügyvédi irodák, illetve a különböző intézmények többnyire érzékeny adattal vagy üzleti titokkal dolgoznak, amit például nem is szabad nekik más vállalatok, így pl. az OpenAI szervereire feltölteni. Ezzel viszont épp a legfontosabb képességeit nem lehet ezeknek a megoldásoknak kihasználni.
A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. ezért egy közös kutatásban azt vizsgálta, hogy egy kisebb, kevesebb erőforrásigényű nyelvi modell esetében mennyire lehet kihasználni annak Few-shot Learninges adaptációs képességeit biztonságos környezetben. Azt vizsgáltuk meg elsősorban, hogy mennyire teljesít jobban egy hagyományosabb gépi tanulási megoldáshoz képest. A cikk hátralevő részében bemutatjuk, hogy mit jelent pontosan a Few-shot Learning, mi különbözteti meg más Meta-learning megoldásoktól, és hogy milyen adathalmazt használtunk fel a kutatáshoz. A következő részben pedig bemutatjuk a megoldásunk legfőbb eredményeit. Akit a teljes kutatásunk és annak összes eredménye érdekel, az megtalálja a teljes tanulmányt itt.
A Few-shot Learning megoldás lényege
A Few-shot Learning a gépi tanulás és a Meta-learning viszonylag friss részterülete, aminek az a lényege, hogy akkor is lehessen hatékony mesterséges intelligencia modelleket fejleszteni, ha csak kevés tanítóadat áll rendelkezésre, és nincs mód tanítóadatok gyártására, vagy csak nagyon erőforrásigényesen. Ezeknek a megoldásoknak több típusa van aszerint, hogy a kategóriarendszerünkben hány különböző kategóriát különböztetünk meg, illetve az egyes kategóriákhoz hány darab adat tartozik, amit a fejlesztéshez fel tudunk használni. Ezeket a különböző megoldásokat N-way K-shot elnevezésekkel különböztetik meg, ahol az N azt jelöli, hogy hány kategóriát kell megkülönböztetni az adathalmazon belül, a K pedig az egyes kategóriákhoz tartozó tanítóadatot. Tehát, ha 10 különböző kategóriánk van és azokhoz minden egyes esetben 50 tanítóadatot használunk fel, akkor 10-way 50-shot típusú Few-shot Learningről beszélünk.
Emellett a Few-shot Learningnek van két külön nevesített típusa, a One-shot Learning és a Zero-shot Learning. A One-shot Learning lényege, ahogy a nevéből is ered, hogy minden egyes kategóriához csak egy darab tanítóadat áll rendelkezésre. Ilyen típusú feladat például a telefonokhoz és más egyéb eszközökhöz használt arcfelismerő alkalmazások fejlesztése, hiszen az egyes emberekhez többnyire csak egy arc tartozik, amit fel lehet használni a rendszerek pontos betanításához. Zero-shot Learningről pedig akkor beszélünk, ha az egyes kategóriákhoz egyáltalán nem áll rendelkezésünkre tanítóadat, csupán a kategóriák elnevezésének szemantikai jelentését használja fel a modell. Bizonyos feladatok esetében ezt láthatjuk a már említett nagy nyelvi modellek esetében is.
Viszont legyen szó, akár N-way K-shot típusú, akár One-shot vagy Zero-shot Learningről, ezeknek a megoldásoknak a lényege, hogy az algoritmus a rendelkezésre álló példák alapján az egyes csoportokat leképzi egy vektortérbe (vagyis numerikus formára alakítja úgy, hogy a gép számára is értelmethető legyen, illetve, hogy a hasonló témához tartozó dokumentumok egymáshoz közel kerüljenek), és az új, beérkező adatokról el tudja dönteni, hogy melyik csoporthoz tartozó dokumentumokhoz áll a legközelebb és az alapján fel tudjuk címkézni. Az ilyen hasonlóság típusú leképezéshez a vektortérben több lehetséges módszer is rendelkezésre áll, ezek közül az egyik leggyakoribb, amit mi is használtunk, az a sziámi hálón alapuló megoldás. Ez a módszer abban különbözik a hagyományos felügyelt tanítástól (ahol szintén a vektortérben igyekszünk leképezni az adatokat úgy, hogy a hasonlók egymáshoz közel legyenek), hogy nem egy adat, illetve kimeneti címke párosítást használunk a tanításhoz, mint a felügyelt tanítás esetében, hanem 2 vagy 3 adatot és a hozzájuk tartozó kimeneti értékeket. A sziámi hálók esetében így tulajdonképpen kétfajta tanítási mód az elterjedt. Az egyik a páros hasonlóság alapú tanítás, ahol mindig két azonos kimenetelű adatot választunk ki és így párosával tanítjuk fel a hálót. A másik a triplet loss tanítás, ahol mindig egyszerre 3 különböző elemet választunk ki a háló kialakításához. Az első az úgynevezett anchor (horgony), egy véletlenszerűen kiválasztott elem az adathalmazból. A második egy pozitív, ugyanahhoz a kategóriához tartozó másik elem, a harmadik pedig egy negatív, egy véletlenszerűen kiválasztott másik kategóriához tartozó elem. Ezekkel az adatpárokkal vagy adattriókkal pedig ki tudunk alakítani egy struktúrát, ami aztán képes az új adatokat megfelelően klasszifikálni úgy, hogy kevesebb adatot használunk fel, mint egy hagyományos gépi tanulási projekt esetén.
A kutatás során alapvetően arra voltunk kíváncsiak, hogy egy ilyen triplet lossos sziámi háló tanítás révén mennyivel kevesebb tanítóadatra van szükségünk ugyanolyan eredmény eléréséhez ugyanazon az adathalmazon, mint egy hagyományos gépi tanulási projekt esetén. Emellett megvizsgáltuk, hogy ha egy új kategóriát szeretnénk felvinni a rendszerbe, akkor az mennyivel egyszerűbb, mint más megoldások esetén. Végül pedig, mivel a triplet loss típusú sziámi háló alapú Few-shot Learning megoldásokat alapvetően olyan adatokra szokták alkalmazni, ahol minden egyes adathoz egy fix kategória tartozik, viszont a jogi dokumentumok természete alapvetően olyan, hogy többnyire egy dokumentumot több kategóriába is be lehet osztani, emiatt fontosnak tartottuk megvizsgálni, hogy a Few-shot Learning hogyan működik multi label esetben, tehát, amikor egy adat több kategóriába is besorolódhat.
A kutatást a Wolters Kluwer Hungary Kft. Jogtár rendszerében lévő Adózási joggyakorlathoz tartozó dokumentumokon végeztük el. Azért esett erre az adathalmazra a választás, mert alapvetően rövid dokumentumokról van szó, így nem okozott gondot, hogy beférjünk az általunk használt kisebb nyelvi modell, a magyarra tanított BERT kontextusablakába. Emellett azért is volt szerencsés a választás, mert egy korábbi fejlesztés során az Adózási joggyakorlathoz tartozó dokumentumokra már készítettünk egy Transfer learningre épülő automatikus kategorizálót, a korábbi bírósági határozatokra kialakított kategóriarendszerünk segítségével. A Transfer learning lényege röviden összefoglalva, hogy amennyiben már egy adott kategóriarendszerre létezik egy modellünk, ami az automatikus besorolását elvégzi az adatoknak, akkor annak a modellnek új típusú dokumentumokat mutatva azokra a dokumentumokra is finomítani tudjuk a modellt, hogy ugyanabba a kategóriarendszerbe vagy annak egy részébe csoportosítani tudja az új típusú dokumentumokat. Így a modell fel tudja használni a tudását, amit a korábbi adathalmazon szerzett és azt is, amit az újon. Ennek az előnye az volt a kutatás szempontjából, hogy már rendelkezésünkre állt egy kategóriahalmaz, illetve jó összehasonlítási alapot jelentett, amivel a hagyományos felügyelt tanítás, a Transfer learning, valamint a Few-shot Learning eredményeit össze tudtuk hasonlítani. A cikksorozat következő részében bemutatjuk, hogy pontosan milyen architektúrát használtunk a kutatáshoz és milyen eredményeket értünk el ezen az adathalmazon.
A kutatásról készült teljes, angol nyelvű tanulmány letölthető innen.


A tanulmány szerzői:
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője;
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője;
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója,
- Fülöp Anna, a Wolters Kluwer Hungary Kft. szerkesztőségi főmunkatársa;
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője;
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója;
- Üveges István, a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője, valamint a HUN-REN Társadalomtudományi Kutatóközpont projektkutatója.