Végre van egy definíciónk a nyílt forráskódú mesterséges intelligenciára
A kutatók hosszú ideje nem értenek egyet abban, hogy mi minősül nyílt forráskódú mesterséges intelligenciának. Egy befolyásos csoport most felajánlott egy választ.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Mi köze az anonimizált bírósági határozatoknak a kék nyakkendős emberekhez? Hogyan tanul az algoritmus, és milyen módszereket használt a Döntvénytár fejlesztői csapata a legújabb keresési lehetőség bevezetéséhez? Most beláthatnak a kulisszák mögé az olvasók: így készült a Jogtár legfrissebb fejlesztése.
A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közös kutatás-fejlesztési együttműködése során a bírósági határozatok pertárgy szerinti automatikus kategorizálásával, ún. címkézéssel foglalkoztunk. A Jogtáron a Döntvénytár felhasználói már “kézbe vehették”, és kipróbálhatják az újfajta keresési és szűrési lehetőséget, azonban egy ilyen gépi tanuláson alapuló projekt korántsem magától értetődő.
Az ezzel kapcsolatos eredményeinkről és tapasztalatainkról ezért most egy cikksorozat keretében olvashatnak az érdeklődők. A projekt során megoldandó problémákról bevezető jelleggel az első részben írtunk. Most pedig rátérünk a kategorizáláshoz használt címkerendszer kialakításának fő lépéseire. A harmadik befejező részben a kialakított gépi tanulási modellek legfőbb eredményeit fogjuk ismertetni.
A címkerendszer kialakításának módszerei
Ahogy az előző cikkben bemutattuk, az első pertárgy szerinti címkéző algoritmusunk fejlesztése során az volt a tapasztalatunk, hogy a kategóriarendszer kialakítása sok szempontból nagyban befolyásolja az elkészült gépi tanulási modell hatékonyságát. Ezért az új projektünkben kialakítottunk egy komplex módszertant, amelynek elemei között volt egy jogszabályokra alapuló szabályalapú megközelítés (Rule-based method), különböző nem-felügyelt tanításon alapuló megoldások (Unsupervised Learning), és különböző statisztikai megközelítések, mint például az egymást átfedő címkék kiszűrése.
Szabályalapú megközelítés
A projekt során tehát a végcélunk az volt, hogy úgynevezett felügyelt tanításon alapuló gépi tanulási modelleket hozzunk létre a bírósági határozatok pertárgy szerinti automatikus kategorizálásának érdekében. A gépi tanulás a mesterséges intelligencia fejlesztések egyik változata, lényege, hogy az emberi tanulási folyamatot mintázva adatok alapján elősegítse többek között a döntési és előrejelzési feladatok elvégzését. Az egyik legnagyobb részterülete a felügyelt tanítás, aminek a lényege, hogy bizonyos mennyiségű adatot előre felcímkézünk, az algoritmus ez alapján rátanul az egyes címkék attribútumaira, és ha érkezik egy új adat, akkor automatikusan el tudja dönteni, hogy az melyik kategóriába tartozik. Például, ha egy konferenciateremben összecsoportosítjuk a kék nyakkendővel rendelkező embereket, illetve egy másik csoportba rendezzük a kék nyakkendővel nem rendelkező embereket, és a gépnek azt mondjuk, hogy az ő segítségükkel tanulja meg, milyenek a kék nyakkendősök, akkor ha egy új ember érkezik a terembe, az algoritmus el tudja dönteni, hogy ő kék nyakkendős-e vagy sem.
Az ilyen típusú fejlesztésekhez tulajdonképpen két dologra van szükség: egyrészt egy stabil kategóriarendszerre, ugyanis a felügyelt gépi tanulási algoritmus a fluid, változó kategóriákkal nem igazán tud mit kezdeni, másrészt az egyes címkékhez megfelelő mennyiségű és minőségű tanítóadatra. Utóbbira azért van szükség, mert ha kevés az adat, akkor az algoritmus nem fogja tudni, hogy melyek azok az attribútumai az adatnak, amire rá kell tanulnia. Például, ha csak egy kék nyakkendős embert mutatunk meg neki, akkor nem fogja tudni, hogy most akkor pontosan a nyakkendőre, a zakóra vagy a cipőre kell-e rátanulnia. Emellett fontos az is, hogy a tanítóadat minősége jó legyen, tehát hogy ne kerüljenek olyan emberek a tanítóhalmaz pozitív elemei közé, akiknek nincs nyakkendőjük, vagy olyan a nyakkendőjük árnyalata, amiről még az emberek egy része is azt mondja, hogy kék, más részük szerint viszont zöld.
A bírósági határozatok felügyelt tanításon alapuló kategorizálásához nekünk is ezekre volt szükségünk. Ezért a korábbi projekt tapasztalataiból tanulva mindenekelőtt kialakítottunk egy olyan kategóriarendszert, ami a bírósági határozatok minél szélesebb körét lefedi, és amely a jogi dogmatika szabályszerűségein túl figyelembe veszi a mesterséges intelligencia fejlesztéshez szükséges sajátszerűségeket is. A kategóriarendszer kialakítása során így mindenekelőtt arra voltunk figyelemmel, hogy minden egyes kialakítandó címkéhez megfelelő mennyiségű tanítóadat (vagyis dokumentum) álljon majd később rendelkezésre az algoritmikus modellek kialakításánál, valamint, hogy az egyes címkékhez nagyjából azonos mennyiségű dokumentum tartozzon, mert azt korábban láttuk, hogy felhasználói szempontból sem előnyös, ha bizonyos címkék túl specifikusak, míg más címkék túl általánosak. Emellett figyelemmel voltunk arra is, hogy a címkék között ne legyen túlságosan nagy az átfedés a dokumentumok tekintetében, mert az az algoritmus tanulási folyamatát nehezíteni tudja, ha nem tudja pontosan elhatárolni egymástól a címkék attribútumait.
Ezért döntöttünk amellett, hogy a bírósági határozatok pertárgy szerinti kategorizálásához egy új, hierarchikus címkerendszert hozunk létre. A hierarchikusság ugyanis lefedi a jogi logika alapvető sajátszerűségeit, vagyis hogy a legtöbb jogi kategória általában besorolható valamilyen más nagyobb tárgykörbe is, valamint az adathalmaz statisztikai és nyelvi megközelítéséhez is közelebb áll, mint a korábban alkalmazott egyszintű kategóriarendszer. Továbbá az algoritmus számára is előnyös, hogy ha pontosan nem tudja meghatározni, hogy az adott dokumentum melyik specifikus címkéhez tartozik, akkor még mindig be tudja sorolni annak a magasabb kategóriájába. Emellett pedig felhasználói szempontból is előnyös, hogy a felhasználó magának tudja eldönteni, hogy mennyire specifikusan szeretne keresni, és mennyire szeretné leszűrni a találati listáját. A kategóriarendszer struktúrájának kialakításához pedig mindenekelőtt a határozatokban lévő jogszabály-hivatkozásokat használtuk fel.
A kategóriarendszer kialakításánál használt alapvető módszertan az volt, hogy az általánostól a specifikusig haladva igyekeztünk a bírósági határozatok halmazát minél részletesebben felbontani. Ennek első lépése az volt, hogy a dokumentumokat szétosztottuk jogterületek szerint. Ezt követően az egyes jogterületeken belül az adott jogterület meghatározó törvényeinek szerkezete alapján kijelöltük az adott jogterület jogalkalmazás tekintetében releváns főbb csomópontjait. A felhasznált jelentős törvények a munkajog esetében például a Munka törvénykönyve, a közalkalmazotti és más szolgálati jogviszonnyal kapcsolatos törvények voltak; a büntetőjog és a katonai büntetőjog esetében a Btk.; a polgári és a gazdasági jogterületen pedig a Ptk., és a régen a Ptk. rendszerén kívülálló jogszabályok, mint a Gt. vagy a Cstv. Illetve minden esetben, ha az adott törvénynek régi és új verziója is volt, akkor annak mindegyik verzióját felhasználtuk figyelve az esetleges szerkezeti változásokra. A jogszabályhivatkozásokat pedig nem csak paragrafus szintig, hanem bekezdés szintig tudtuk kezelni, ami lehetővé tette, hogy minél részletesebben meg tudjuk különböztetni az egyes jogi témaköröket. A közigazgatási jog esetében részben eltérő módszertant követtük, erről később írunk részletesen.
A közigazgatási jogterületen kívül a többi jogterületnél az volt tehát az eljárásunk, hogy azonosítottuk a fő témaköröket, és reguláris kifejezések segítségével, valamint a MONTANA saját fejlesztésű jogszabályhely-kinyerőjének és előfeldolgozási eszközeinek a segítségével megnéztük, hogy hány olyan határozat van, amely azokra a jogszabályhelyekre hivatkoznak, amelyek az adott témát lefedik.
A reguláris kifejezés (Regular Expression) tulajdonképpen nem más, mint egy karaktersor, amit keresőkifejezésként használunk, hogy bizonyos adatelemeket megtaláljunk a szövegen belül, jelen esetben a jogszabályhelyekre történő hivatkozást. A jogszabályhely-kinyerő használata és a szöveg előfeldolgozása, különösen a jogszabály-hivatkozások normalizálása pedig azért volt fontos, mert a határozatok szövegében a jogszabályokra történő hivatkozás eltérő módokon történhet, illetve sok elírást is tartalmazhat. A MONTANA eszközei azonban képesek felismerni a jogszabály-hivatkozásokat akkor is, ha azok atipikus módon vannak kifejezve, és azokat egységes szerkezetre tudja hozni, így az azokra történő keresés során nem kell minden lehetséges változatot beírni, hanem elég az egységes formátumra szűrni.
Ezeknek az eszközöknek a segítségével tehát meg tudtuk határozni, hogy bizonyos jogszabályhely csoportok, amik egy-egy témához tartoznak, hány darab bírósági határozatban fordulnak elő. Így pedig a témaköröket le tudtuk bontani akár mélyebb altémakörökre is egészen addig, amíg nem érkeztünk el arra szintre, amikor már túl részletes a szétbontás. A munkajogi jogterületen belül például sikerült azonosítanunk a “Munkaviszony megszüntetése” témát és megállapítottuk, hogy annak a jogszabályhelyei több, mint 2000 darab dokumentumban fordulnak elő. Ezt így túl tág halmaznak ítéltük meg, ezért ezt még felbontottuk tovább “Munkaviszony közös megegyezéssel történő megszüntetése”, “Munkaviszony felmondása”, “Munkaviszony azonnali hatályú felmondása” és “Csoportos létszámcsökkentés” altémákra. Ezt követően megnéztük, hogy a felmondás és az azonnali felmondás címkék tovább bonthatóak-e aszerint, hogy munkavállaló vagy munkáltatói felmondásról/azonnali felmondásról van szó, itt viszont azt láttuk, hogy a munkavállalói részek ezeknél kevesebb, mint 100 dokumentumot tartalmaznak, ezért az előző szintnél megálltunk, mert ezt már túl részletesnek találtuk, és nem lett volna megfelelő mennyiségű tanítóadat hozzá.
Miután az adott jogterület előzetesen azonosított releváns jogszabályhelyein ezzel az eljárással végigmentünk, ellenőrizni kellett, hogy nem marad-e ki valamilyen fontos terület, amire előzetesen nem gondoltunk. Ezt úgy tettük meg, hogy a reguláris kifejezésekben összefűztük a már felhasznált jogszabályhelyeket és megnéztük egyrészt azt, hogy a teljes dokumentumhalmaz mekkora hányada marad ki, amik nem tartalmazzák a felsorolt jogszabályhelyeknek valamelyikét, másrészt pedig azt, hogy vannak-e olyan jogszabályhelyek, vagy egy-egy témához azonosíthatóan tartozó jogszabályhely-csoportok, amelyek kimaradtak az előzetesen azonosítottak közül.
Ha pedig voltak ilyenek, akkor azonosítottuk, hogy azok milyen témához tartoznak, és ha már létező témához tudtak kapcsolódni, akkor azokhoz hozzátettük paraméternek, ha viszont olyan témakört fedtek le, amelyet addig nem fedtünk le, és a jogi szakértők szerint releváns, akkor felvettük a kategóriarendszerbe. Így jött létre többek között a “Rendvédelmi szervek hivatásos állományú tagjai” elnevezésű címkecsoport, mert előzetesen nem gondoltunk arra, hogy az releváns téma lehet a bírósági határozatok esetében, de az így kialakított szabályalapú eljárás statisztikái azt mutatták, hogy mégis az, ezért felvettük a kategóriák közé.
Ezt az eljárást addig folytattuk, amíg voltak olyan jogszabályhely-csoportok, amelyeket nem használtunk fel, viszont nagy mennyiségű, az addig használt jogszabályhivatkozások alapján ki nem szűrt dokumentumban előfordultak. Ezzel a módszerrel sikerült minden jogterület esetében jelentősen lecsökkenteni azoknak a dokumentumoknak az arányát, amelyek a jogszabály-hivatkozások alapján nem kapnának címkét. Ez azért is volt hasznos, mert a gépi tanulási modellek számára ez így már kezelhető mennyiségű határozat, amelyeknek a nagy részét be tudja sorolni releváns címkékbe az algoritmus a feltanítás után, minimálisra szorítva az “Egyéb” kategóriába tartozó dokumentumok számát.
Ahogy említettük ezt az eljárást a munkajogi, a katonai büntetőjogi, illetve büntetőjogi, valamint a polgári és a gazdasági jogterületek esetében tudtuk használni. A közigazgatási jogi jogterület esetében viszont tulajdonképpen fordított módon jártunk el, ennél a jogterületnél ugyanis nem tudtunk azonosítani markáns, a jogterület széles dokumentumait lefedő anyagi jogi jogszabályt.
Ezért első körben, az eljárási jogszabályok, mint például az Ákr., Kp., kiszűrése után megnéztük, hogy melyek a legtöbbször előforduló releváns anyagi jogi jogszabályok, és ezek azonosításával alakítottuk ki a jogterület kategóriarendszerét. A közigazgatási jogterületen belül legtöbbször hivatkozott jogszabályok egyébként az adózási tárgyú jogszabályok, majd az építésügy, aztán idegenrendészet, és így tovább. Ezt az eljárást, az előzőhöz hasonlóan, addig folytattuk, amíg voltak olyan jogszabályhely-csoportok, amelyek nagy számú dokumentumban előfordultak, valamint nagy volt azoknak a határozatoknak az aránya, amelyek kívül esnek az addigi kategóriarendszeren.
Ezekkel a módszerekkel pedig elkészült minden egyes jogterülethez a szabályalapon kidolgozott hierarchikus kategóriarendszer nagyjából 90%-os váza:

Az ábra a munkajogi jogterület címkéit mutatja a szabályalapú módszerek által kapott számosságok első elemzése után. A diagram hierarchikusan összerendeződő címkék egymáshoz való viszonyát is ábrázolja. A belső címkék a főkategóriák, amik aztán így oszlanak szét altémakörökre. A kördiagram egyes szeleteinek nagysága az egyes címkékhez tartozó dokumentumok számosságának hozzávetőleges arányát mutatja.
Ezt követően a Wolters Kluwer Hungary és a MONTANA jogi szakértői, valamint adatelemzői ezekből kiindulva, különböző statisztikai adatokat összevetve kialakították a végleges címkerendszert, amelyre az egyes gépi tanulási modelleket kifejlesztették. Az egyik legfontosabb statisztikai mutató, amit használtunk, az az egyes címkék közötti átfedések vizsgálata. Az előző cikkben ugyanis bemutattuk, hogy előző projekt tapasztalataiból azt szűrtük le, hogy egyrészt a gépi tanulás hatékonyságát is rontja, ha túl nagy az átfedés egyes címkék között, mert az algoritmus nem fogja tudni elkülöníteni az attribútumokat, másrészt pedig logikailag sem feltétlenül szükségszerű, hogy megkülönböztessünk két külön címkét, ha azoknak a dokumentumai egyébként nagyrészt azonosak. Emellett pedig felhasználtunk különböző unsupervised learningre (nem felügyelt tanításra) alapuló eszközöket a kategóriarendszer pontos kialakításához, ezeket a következő alfejezetben mutatjuk be.
Unsupervised eszközök
Ahogy említettük a nem felügyelt tanítás a felügyelt tanításhoz hasonlóan szintén a gépi tanulás egyik legfontosabb alkategóriája. A különbség a két eljárás között, hogy míg a felügyelt tanítás esetében rendelkezünk az egyes címkékhez tanítóadattal, és az algoritmus azok alapján tanul rá az egyes kategóriák főbb attribútumaira, ami alapján egy új adatról el tudja dönteni, hogy ahhoz a kategóriához tartozik-e vagy sem, addig az unsupervised learningnél nincs tanítóadatunk, sőt még kidolgozott kategóriarendszerünk sem feltétlenül, hanem csak a kérdéses dokumentumhalmazunk és azt adjuk oda az algoritmusnak, hogy a dokumentumok szabályszerűségeit felismerve automatikusan sorolja őket különböző csoportokba. Ennek az eljárásnak az a hátránya, hogy a kialakult kategóriák kevésbé lesznek szofisztikáltak, és az egyes címkék alá tartozó dokumentumok kevésbé pontosak, mint a felügyelt tanítás esetén, viszont tökéletesen alkalmazható arra, hogy azoknak az adathalmazoknak az esetében, ahol nem tudunk semmit az adat természetéről, segítsen strukturáltabbá tenni az adathalmazt és bizonyos információkat szolgáltatni a természetéről. Emellett, ahogy a mi esetünkben is, segíthet ellenőrizni azt, hogy az általunk emberek által kialakított kategóriarendszer és azok fő témái mennyire egyeznek azzal, amelyet más eljárás szerint a gép alakítana ki a saját szabályszerűségeit felhasználva. Ez segíthet abban, hogy az ilyen munkák során az emberi gondolkodást jellemző korlátokat minél inkább minimálisra szorítsunk.
A projekt során kétfajta megoldást használtunk kétfajta cél elérésére: egyrészt TF-IDF vektorizálás után használt K-means Clustering algoritmust, valamint egy úgynevezett Latent Dirichlet Allocation megoldást. A TF-IDF (vagyis Term Frequency Inverse Document Frequency) egy régóta ismert vektorizálási forma, ami statisztikai alapon súlyozza a dokumentumban előforduló szavakat aszerint, hogy az adott dokumentumban milyen gyakran fordul elő a szó (term frequency), illetve, hogy a teljes adathalmaz összességében hány dokumentumban fordul elő ugyanaz a szó (inverse document frequency). Ha egy kifejezés például csak pár dokumentumban fordul elő, akkor az idf értéke magasabb lesz ennek a szónak, mint egy olyan szónak, aminek az előfordulása általánosabb a corpusban. Ennek az előfeldolgozási módnak a segítségével pedig a bírósági határozatok, illetve a bennük lévő szavak a számítógép által is feldolgozható numerikus formára kerülnek.
A K-means Clustering pedig tulajdonképpen egy automatikus csoportosítást segítő megoldás, amely első körben meghatározza, hogy mi az ideális kategóriaszám egy adott dokumentumhalmazon belül, majd az így kapott ideális számú kategóriába besorolja a dokumentumokat. Ennek a megoldásnak a korlátja, hogy egyszintű kategóriarendszerekre lehet tökéletesen alkalmazni, mert az egyes kategóriákon belüli alkategóriákat már nem képes megkülönböztetni, ezért a miénkhez hasonló hierarchikus rendszerek megsegítéséhez nem magától értetődő a használata. Ahhoz viszont jól használható, hogy az egyes kategóriákon belül az ideális számú alkategóriát meghatározzuk, és a hierarchiarendszerben egyre mélyebbre menve egyesével térképezhessük fel a címkerendszer hálóját. Ez látható a lenti ábrán a “Munkaviszony megszüntetése” címkén szemléltetve.
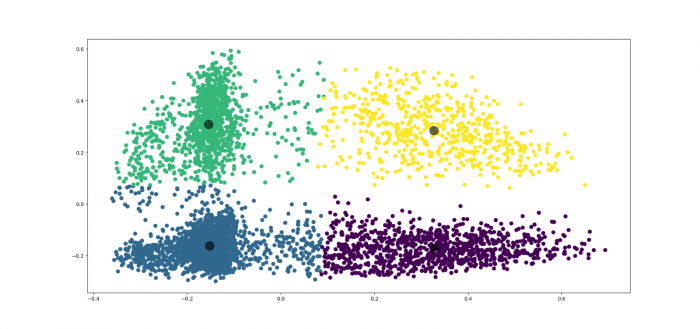
A “Munkaviszony megszüntetése” főkategóriát az Mt. szerkezetének és a jogszabályhivatkozások felhasználásával szabályalapon 4 kategóriára osztottuk. Jól látszik, hogy a K-means Clustering algoritmus is ennyi kategóriára osztja minden előzetes tudás nélkül, viszont itt látszik az is, hogy az egyes kategóriák között mekkora az átfedés.
A Latent Dirichlet Allocation (LDA) ezt egészíti ki azzal, hogy ez a fajta csoportosítás képes megtalálni, hogy egy adott dokumentumhalmazban milyen különböző témakörök léteznek az által, hogy az adott csoportnak mik a meghatározó szavai kifejezései. Az alábbi ábra ezt szemlélteti, hogy a munkajogi jogterületen belül van egy olyan témakör, amelynek a meghatározó szavai a “fizetés fokozat”, “ágazat pótlék”, “rendvédelem”, illetve “rendvédelem ágazat” (a szavakat minden dokumentum esetében szótöveztük, ezért a kicsit magyartalan megfogalmazás). Ez azt jelenti, hogy mindenképp érdemes a rendvédelmi jogviszonnyal rendelkezőkkel kapcsolatban címkét felvenni, különösen azok illetményével kapcsolatban.
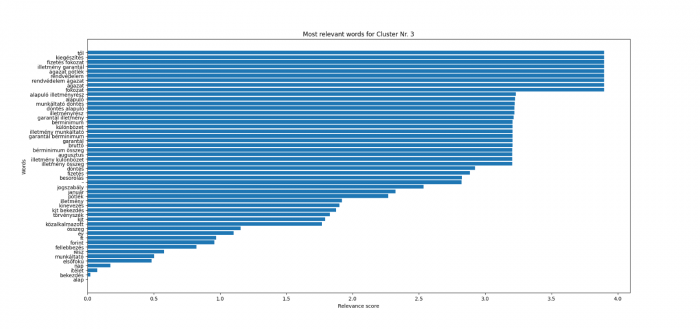
A munkajogi jogterület 3-as számú automatikusan, LDA megoldással képzett csoportjának legrelevánsabb szavai, kifejezései.
Ez természetesen nem minden esetben ad használható eredményt, hiszen a témakörök nem feltétlenül csak egy csoportra jellemzőek, illetve lehetnek ember számára kevésbé értelmezhetőek is. Ahogy ugyanis a lenti ábrán is lehet látni ez a megközelítés az olyan többnyire eljárási kifejezések miatt is kialakít egy kategóriát, mint “másodfok perköltség”, “illeték” és “perköltség”. Ez természetesen az LDA algoritmus működése szempontjából logikus, viszont a mi kategória kialakítási megközelítésünk szempontjából nem használható.
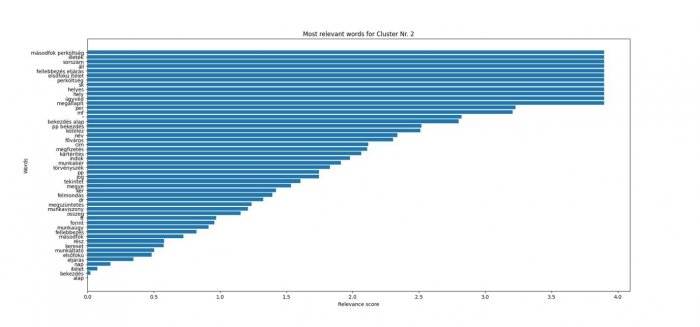
A munkajogi jogterület 2-es számú automatikusan, LDA megoldással képzett csoportjának legrelevánsabb szavai, kifejezései.
Összefoglalva tehát a nem felügyelt tanításon alapuló megoldásokat arra lehet használni, hogy meghatározzuk, mennyi az ideális kategóriaszám egy dokumentumhalmazon belül, valamint, hogy meghatározzuk, hogy az egyes kategóriáknak melyek a meghatározó kulcsfogalmai. Ezekkel az eszközökkel pedig a szabályalapon kialakított kategóriarendszerünket még jobban tökéletesíteni tudtuk, hogy ne csak jogi dogmatikai szabályszerűségei és a jogászi megközelítés domináljon, hanem felhasználhassuk a bírósági határozatok statisztikai és nyelvtani szabályszerűségeit is, hogy a Jogtár felhasználók számára minél jobb pertárgy szerinti szűrés álljon rendelkezésre. Így tehát végeredményben előállt a kategóriarendszerünk, illetve az egyes címkékhez megfelelő mennyiségű tanítóadat, amely segítségével le tudtuk fejleszteni az egyes címkékhez a felügyelt tanításon alapuló gépi tanulási modelleket.
Ez a bírósági határozatokat pertárgyak alapján hierarchikus címkerendszer szerint automatikusan kategorizáló gépi tanulási projektjéről szóló cikksorozat második része, a címkerendszer kialakítása során alkalmazott módszertan részletes bemutatásáról. Az első cikkben bemutattuk a projekt során felmerülő és megoldásra váró problémákat, az utolsó részben pedig bemutatjuk az így előállított felügyelt tanításon alapuló gépi modellek teljesítményének főbb eredményeit.
![]()
![]()
A cikk szerzői: