Végre van egy definíciónk a nyílt forráskódú mesterséges intelligenciára
A kutatók hosszú ideje nem értenek egyet abban, hogy mi minősül nyílt forráskódú mesterséges intelligenciának. Egy befolyásos csoport most felajánlott egy választ.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Jogtár újdonság: gépi tanuláson alapuló hierarchikus címkéző algoritmust fejlesztett közösen a WK Hungary és a Montana szakértői csapata, melynek eredményei e cikksorozat keretében ismerhetőek meg, a Jogtár felhasználók pedig már a felületen is használhatják az újfajta pertárgy keresőt.
A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közös kutatás-fejlesztési együttműködése során a bírósági határozatok pertárgy szerinti automatikus kategorizálásával, ún. címkézéssel foglalkoztunk. A Jogtáron a Döntvénytár felhasználói már használhatják és kipróbálhatják a legújabb fejlesztést a Döntvénykeresőben, illetve a találati lista Pertárgy szűrési funkciójánál.
Az ezzel kapcsolatos eredményeinkről és tapasztalatainkról szóló cikksorozat első részében a projekt során megoldandó problémákról, a második részben pedig a kategorizáláshoz használt címkerendszer kialakításának fő lépéseiről írtunk. A cikksorozat jelen, befejező részében pedig a fejlesztéshez használt gépi tanulási modellek legfőbb eredményeit mutatjuk be.
Felhasznált gépi tanulási eszközök
Ahogy a korábbi cikkekben is írtuk, a célunk felügyelt tanításon alapuló gépi tanulási modellek létrehozása volt a bírósági határozatok pertárgy szerinti automatikus kategorizálásához. A felügyelt tanítás tulajdonképpen nem szól másról, minthogy az algoritmusnak megmutatunk pár előre felcímkézett dokumentumot, úgynevezett tanítóadatot, és azok alapján rátanul ezeknek a dokumentumoknak a közös szabályszerűségeire, ami alapján egy új dokumentumról el tudja dönteni, hogy arra a dokumentumra ráillik-e az adott címke, vagy nem. Ez a megoldás használható akkor is, ha csak egy címkét adhatunk egy dokumentumra, de akkor is, ha egyszerre több címke (azaz több pertárgy) is rákerülhet a dokumentumokra, mint a mi esetünkben. Ehhez tulajdonképpen nincs szükség másra, mint megfelelő mennyiségű és minőségű tanítóadatra. A korábbi cikkben bemutattuk, hogy ebben a projektben ezeket hogyan állítottuk elő, úgyhogy nem maradt más hátra, mint a modellek lefejlesztése.
Egy gépi tanulási fejlesztésnél, amiket meg kell határozni az az, hogy milyen formában reprezentáljuk a szöveget a számítógép számára, tehát milyen előfeldolgozási módszereket használunk a szövegeknél, milyen konkrét modelleket használunk, illetve, hogy hogyan, milyen szempontok szerint értékeljük ki az egyes megoldások hatékonyságát. Ezeket a lépéseket a projekt során minden egyes jogterület esetében megtettük annak érdekében, hogy ki tudjuk választani minden esetben az adott jogterület címkéinek automatikus kategorizálásához szükséges leghatékonyabb mesterséges intelligencia megoldást. A következő alfejezetekben ezeket a lépéseket mutatjuk be részletesen a munkajogi jogterület eredményein keresztül.
Előfeldolgozás
Az előfeldolgozás a gépi tanulási projektek fontos lépése, amely során az adat valamilyen szempont szerint manipulálásra kerül annak érdekében, hogy a gép által jobban feldolgozható legyen, és ezáltal a gépi tanulási folyamat hatékonyságát javítani lehessen. A projekt során ezért megnéztük, hogy hogyan befolyásolja a modellek hatékonyságát, ha nem használunk előfeldolgozást (raw – az elnevezésekhez tartozó eredmények az első ábrán láthatók), ha kisbetűsítjük a szöveget (lower), ha kiszedjük a központozást (punct), ha egyszerre kisbetűsítünk és kiszedjük a központozást (lower_punct), ha egyszerre kisbetűsítünk, kiszedjük a központozást és szótövesítjük a szavakat (lower_punct_stem), valamint ha mindezek mellett még kinyerjük a jogszabály-hivatkozásokat is és normalizáljuk azokat, tehát megszüntetjük a hivatkozási eltérésekből és elírásokból fakadó eltéréseket (broadened_lawref_lower_punct_stem). Az egyes megoldásokat a validációs halmazokon mért pontosság-fedés görbe alatti terület számításával (PR AUC) vizsgáltuk meg, ahol minél nagyobb értéket kapunk 0 és 1 között, annál jobb a modell. Az összehasonlítás érdekében pedig egy diagramon ábrázoltuk őket.
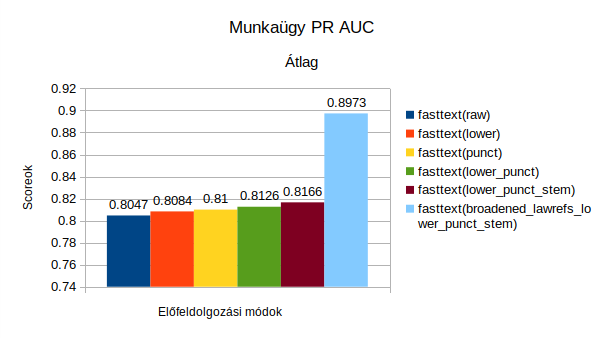
Az előbb felvázolt Fasttextes modell mellett elkészítettük az általunk az egyszerűség kedvéért Sklearnnek nevezett modellre is a kiértékeléseket (hogy a kétfajta megoldás között pontosan mi is a különbség, arra a következő alfejezetben térünk ki). Az Sklearn modell esetében tovább színesíti az is a dolgot, hogy kétfajta változókiválasztási módnak a hatását is megnéztük az eredményekre. A változókiválasztásnak azért van relevanciája bizonyos modellek esetében, mert segít az egyes releváns jellemzők kiválasztásában a modellalkotás során és ezzel lehet javítani a modellek eredményességét.
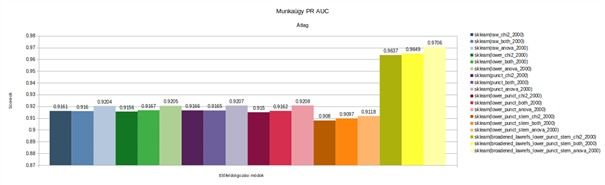
Mindkét ábrán látszik, hogy mindegyik modell és megközelítési mód esetén az teljesített a legjobban, amikor kinyertük a szövegből a jogszabály-hivatkozásokat és normalizált formára hoztuk őket, tehát megszüntettük a hivatkozási eltérésekből és elírásokból fakadó eltéréseket. Ez természetesen annyira nem meglepő eredmény, hiszen logikus, hogy a jogszabály-hivatkozások fontos attribútumai a bírósági határozatoknak, amik a gépi modellek tanulási folyamatát is erősen tudja orientálni, viszont az meglepő volt, hogy mindkét modell esetében ennyire kiemelkedő javulást tudtunk elérni. Emellett pedig ez a vizsgálat hasznos volt arra is, hogy a két diagramon látható eredmények egymással is összehasonlíthatók, ezért kijelenthető az, hogy a validációs halmazon mért eredmények alapján nagy eséllyel tudjuk valószínűsíteni azt, hogy a munkaügyi dokumentumok esetében az Sklearn modell jelentősen jobban tud működni a Fasttext modellnél.
Gépi modellek
Ahogy a fentiekből is kiderül, két gépi tanulási modellnek hasonlítottuk össze a működését és az eredményeit annak érdekében, hogy eldönthessük, az adott jogterület esetén, jelen esetben a munkaügyi dokumentumok esetében, melyik modell használható a leghatékonyabban a határozatok pertárgy szerinti címkézéséhez. A Fasttext a Facebook mesterséges intelligenciával foglalkozó kutatólaborjának (FAIR) megoldása, amely segítségével többfajta felügyelt tanuláson és nem felügyelt tanuláson alapuló gépi tanulási projektet el lehet végezni. A Fasttext egyaránt alkalmazható klasszifikálási feladat megoldására, valamint vektorreprezentációs forma generálásához szövegrészekhez. A nyelvi modell felügyelet nélkül tanul egy nagyobb szövegkorpuszon, felhasználva azt a szabályszerűséget, hogy hasonló kontextusban előforduló szavak hasonló jelentéssel bírnak, illetve a szavakat alkotó szótöredékek is összefüggnek. Az Sklearn valójában egy olyan csomag, amivel többféle hagyományos gépi tanulási algoritmust lehet feltanítani, ezek közül a logisztikus regressziót alkalmaztuk, ami egy szöveg kategorizálásnál bevett algoritmikus megoldás, aminek lényege, hogy a szövegeket szózsákként kezeli és a szövegek vektorsúlya alapján dönti el, hogy beletartozik-e egy adott kategóriába vagy nem. Az egyszerűség kedvéért a szövegben ezekre Sklearn modellekként hivatkozunk.
A korábbi eredményeket validációs halmazon kaptuk, ami azt jelenti, hogy a tanítóhalmazon vizsgáltuk meg a címkézés eredményeit. Hogy ennél pontosabb kiértékelést kapjunk a modellekről a két modell címkézési eredményeit a Wolters Kluwer Hungary Kft. munkatársai által kézzel lecímkézett, azaz pertárgyak szerint besorolt 180 határozat címkéivel is összevetettük. Fontos kiemelni, hogy ennél a 180 dokumentumnál a címkék úgy álltak elő, hogy több Jogtár szerkesztő is átnézte a dokumentumokat, így a címkézés konszenzussal jött létre. Ez természetesen lassította a folyamatot, de a célunk az volt, hogy ennél a 180 határozatnál a címkézés közel tökéletes módon legyen végrehajtva. Az egyes modellek különböző szempontok szerinti eredményeit a következő táblázatban foglaltuk össze. Az egyes kiértékelési metrikák közötti különbséget a következő alfejezetben részletezzük.
A két gépi tanulási modell eredményeinek pontos értékeléséhez referencia pontként feltüntettük azt is, hogy mi történne, ha a dokumentumokat csak az előző cikkben részletezett szabályalapú megközelítéssel címkéznénk fel, tehát az alapján, hogy milyen releváns jogszabály-hivatkozás szerepel az adott határozatban. Emellett kidolgoztunk egy hibrid megoldást is, amely során igyekeztük kiaknázni a szabályalapú és a gépi tanulás alapú megoldások előnyeit. Ilyen volt például, ha a szabályalapú módszer rendszerint túl sok címkével tért vissza egy dokumentum esetében, akkor valamely gépi tanulási módszerrel ezeket a címkéket sorba tudtuk tenni valószínűség szerint, és csak a legrelevánsabbakat tartottuk meg.
Ahogy a cikksorozat előző részében kifejtettük, minden egyes jogterülethez egy hierarchikus címkerendszert hoztunk létre. Ez azt jelenti, hogy részben a dogmatikai szabályszerűségek, részben a statisztikai sajátosságokat felhasználva egy többszintű címkekészletet hoztunk létre, hogy a jogterület témakörei le legyenek fedve, az alsó szintű címkékhez nagyjából azonos számosságú dokumentum álljon rendelkezésre, illetve ne legyen átfedés a címkék között. A kiértékelésnél figyelemmel voltunk erre, ezért a metrikákat külön bontottuk aszerint, hogy csak a címkerendszer első szintjét nézzük, tehát, hogy az általánosabb címkéket mennyire találja meg az algoritmus, illetve hogy ha a címkerendszer egészét nézzük, akkor mennyire találja meg a legspecifikusabb címkéket, ahol azt kell. Az eredmények egy részét az alábbi táblázat tartalmazza.
| Metrikák | Rule-based | Fasttext (jogszabály-hivatkozások normalizálásával) | Sklearn (anova megoldással, jogszabály-hivatkozások normalizálásával) | Hibrid (Fasttext) | Hibrid (Sklearn) | |
| HMC-Loss
|
46,77319 | 34,4519 | 29,05006 | 35,21579 | 33,09174 | |
| Első szintű címkemélység alapján | Pontosság
|
0,71 | 0,79 | 0,8317 | 0,79 | 0,79 |
| Fedés | 0,73 | 0,77 | 0,8 | 0,81 | 0,77 | |
| F1 pont
|
0,72 | 0,78 | 0,8155 | 0,80 | 0,78 | |
| Teljes mélység alapján | Dokumentum szintű teljes egyezés | 38,33% | 32,22% | 42,78% | 39,45% | 41,11% |
| Részleges egyezés | 23,33% | 18,89% | 16,11% | 24,44% | 21,12% | |
| Hierarchikus egyezés | 17,78% | 35,56% | 30% | 25,56% | 24,44% | |
| Nincs egyezés | 20,56% | 13,33% | 11,11% | 10,55% | 13,33% |
Ebből a táblázatból is látszik, hogy a munkajogi dokumentumok címkézése esetén a tesztadatokon mért metrikák alapján az Sklearn modell a legtöbb vizsgált szempont alapján kiemelkedő eredményt ért el a többi modellhez képest. Ezért a munkajogi jogterületű bírósági határozatok automatikus kategorizálásához ezt a modellt választottuk ki, és ha a Jogtár felületén a munkajogi címkék valamelyikére szűr a felhasználó, akkor ez a rendszer segít neki a legrelevánsabb találatokat megmutatni. Ezt az eljárást ezt követően valamennyi jogterület esetén megcsináltuk, hogy minden egyes jogterület esetén ki tudjuk választani azt a megoldást, ami azon a területen a legeredményesebb lesz.
Kiértékelési módszerek
A következőkben egy kis használati segédletet szeretnénk adni a táblázatok könnyebb értelmezésének segítéséhez. A modellek címkézési teljesítményének értékeléséhez háromfajta megközelítést használtunk: címkeszintű kiértékelést, dokumentumszintű kiértékelést, valamint az előző kettő hiányosságait kiegészítő úgynevezett HMC-loss alapú kiértékelést.
Eredmények
A legjobb gépi tanulási megoldást végül összevetettük egy jogi szakértő címkézési teljesítményével. Fontosnak tartjuk ugyanis, hogy a mesterséges intelligencia megoldások ne csak a tökéletes megoldásokhoz, illetve egymáshoz legyenek összemérve, hanem az emberi teljesítményekhez is. Ezzel kapunk ugyanis részletesebb képet arról, hogy a különböző gépi tanulási modellek hogyan teljesítenek a már létező emberi erőforrásra építő megoldásokhoz képest, és így mennyiben képesek kiegészíteni azokat.
A kutatás során egy jogi szakértőnek adtuk oda azt a 180 dokumentumot, amit a WK szerkesztői többszöri átnézéssel, többen, konszenzusos alapon címkéztek fel. A jogi szakértőt arra kértük, hogy a saját tudása alapján a lehető legpontosabb címkét vagy címkéket adja az egyes dokumentumokra. A kapott eredményeket a fent részletezett kiértékelési metrikákkal az alábbi táblázatban foglaltuk össze. A “Human” elnevezés a jogi szakértőt, míg a “Machine” az előzetes eredmények alapján legjobban teljesítő gépi modell, tehát az Sklearn megoldást jelenti.
| Metrikák | Human | Machine |
| HMC-Loss | 25,44 | 29,05 |
| Első szintű címkemélység alapján
Pontosság |
0,87 | 0,8317 |
| Fedés | 0,78 | 0,8 |
| F1 pont | 0,82 | 0,8155 |
| Teljes mélység alapján dokumentum szintű teljes egyezés | 46,11% | 42,78% |
| Részleges egyezés | 15% | 16,11% |
| Nincs egyezés | 10% | 11,11% |
Az eredményekből látszik, hogy a gépi modell ugyan nem tudott tökéletes eredményeket elérni, de a legtöbb metrikában megközelíti az emberi teljesítményt, bizonyosakban pedig ugyan nem sokkal, de túl tudja szárnyalni is azt. Ráadásul ezek mellett sokkal gyorsabban is teszi mindezt, illetve a javíthatósága is sokkal könnyebb, mint az emberi teljesítményé, ezért bátran lehet állítani, hogy a határozatok címkézésében nyugodtan lehet az algoritmusra is támaszkodni.
Elemzés
A projekt során és az azokhoz kapcsolódó különböző kutatásainkból le tudtuk vonni azt az általánost következtetést, hogy az általunk kidolgozott szabály-alapú módszertan a klasszikus gépi tanulási eszközökkel kiegészítve tökéletesen alkalmas arra, hogy akármilyen szakmai domainbe tartozó dokumentumhalmaz automatikus kategorizálását elvégezzük. Ha ugyanis a dokumentumhalmaz szövegeiben van akármilyen olyan szabályszerűség, mint a bírósági határozatok esetében a jogszabály-hivatkozások, akkor tudásalapú, illetve mesterséges intelligencia alapú eszközök keresztezésével az egyébként strukturálatlannak tűnő adathalmaz nagyon könnyen átláthatóbbá és kezelhetőbbé tehető. Ezáltal pedig az adott terület szakmai tudása vegyíthető a mesterséges intelligencia technikai megoldásaival, és a kétfajta megközelítés képes felerősíteni egymást. Ezzel pedig nem csak az olyan monoton és sok potenciális hibát magával hordozó feladatot lehet kiváltani a gép segítségével, mint a dokumentumok címkézése, hanem ennek a módszertannak a segítségével sokkal jobban megismerhetjük a rendelkezésünkre álló adathalmazt, valamint a benne rejlő erőforrásokat, és más adatvezérelt fejlesztésekre is lehetőségünk nyílik.
Konklúzió
A bírósági határozatok mesterséges intelligencia segítségével történő automatikus kategorizálása fontos annak érdekében, hogy a jogász felhasználók a Jogtáron történő forráskutatási munkája eredményesebb és gyorsabb legyen. A Wolters Kluwer Hungary Kft. jogi szakértői, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai, természetesnyelv-feldolgozói, nyelvészeti és fejlesztői szakértői a cikksorozat során bemutatott módon kialakítottak egy komplex módszertant, aminek segítségével létrehozták a bírósági határozatok kategorizálásához szükséges kategóriarendszereket. (A részletesebb módszertan és a további eredmények egy tanulmány keretében kerülnek majd publikálásra.) Ezzel létrejött jogterületenként egy olyan hierarchikus kategóriarendszer, ami képes lefedni a bírósági határozatok szabályszerűségeit, valamint minden címkéhez megfelelő mennyiségű tanítóadatot tartalmaz, amelyek között az átfedést igyekeztünk minimálisra szorítani, és mindegyik esetben a legjobban teljesítő gépi modellt felhasználni
Végül megnéztük, hogy az emberi teljesítményhez képest hogyan teljesítenek az algoritmusok. Ezzel kapcsolatban arra jutottunk, hogy ugyan a gépi tanulási modellek nem tökéletesek, de az emberi munka sem az, és a legtöbb metrika esetén a gép képes megközelíteni az ember eredményességét, ráadásul sokkal kevesebb idő és erőráfordítás alatt, mint az ember.
Ráadásul azt is megállapítottuk, hogy a WK és a MONTANA által kidolgozott komplex módszertan, eljárás és a kidolgozott metrikák nem csak bírósági határozatok esetében használható, hanem más dokumentumhalmaz esetén is fel lehet használni az itt kialakított tapasztalatokat, legyen szó más jogi típusú dokumentumokról vagy nem jogi adatokról.
Ez a bírósági határozatokat pertárgyak alapján hierarchikus címkerendszer szerint automatikusan kategorizáló gépi tanulási projektjéről szóló cikksorozat harmadik, befejező része, a Jogtár felületén is elérhető gépi tanulási modellek eredményeiről. A cikksorozat első részét a megoldandó problémákról itt, a második részét a címkerendszer létrehozásához kialakított komplex módszertanunkról pedig itt lehet elolvasni.
![]()
![]()
A cikk szerzői és a fejlesztés résztvevői: