Útkeresés a bizonytalanságban: szabályozási homokozók a vállalati mindennapokban
A cikksorozat második része gyakorlati módon és a szabályozási homokozók példáján keresztül arra keresi a választ, mit jelenthetnek ezek a vállalati mindennapokban.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
A jog területén is utat tört magának a mesterséges intelligencia: egy ún. multi-label klasszifikáló módszerrel tanították az algoritmust nagy mennyiségű joganyagokon.
Az előző cikksorozatunkban bemutattuk, hogy a Jogtárat kiadó Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. által közösen kifejlesztett automatikus címkéző algoritmus milyen teljesítményt ért el különböző emberi címkézőkkel szemben bírósági határozatok kategorizálásánál. Abból a cikksorozatból kiderült, hogy az algoritmus bizonyos esetekben képes elérni vagy akár felül is múlni a jogi szakértők teljesítményét, de mindenképpen jelentősen képes segíteni egy jogi adatbázis szerkesztőinek munkáját, illetve sokkal gyorsabban dolgozik és az elkövetett hibái is sokkal konzekvensebbek, ezáltal könnyebben javíthatóak.
Ebben az új cikksorozatban azt mutatjuk meg, hogy hogyan is készítettük el pontosan az automatikusan címkéző algoritmust. A következő részekből ki fog derülni, hogy milyen módszereket és eszközöket használtunk fel a gépi tanulási projektünkhöz. Ebben a bevezető részben viszont mindenekelőtt azt mutatjuk be, hogy miért is álltunk neki ennek a feladatnak, illetve milyen nehézségekkel kellett szembesülnünk a projekt elején.
A releváns jogesetek megtalálásának problematikája
Manapság egyre több területen igyekeznek kihasználni a gépi tanulás nyújtotta előnyöket, és a jog területe sem kivétel ez alól: több nemzetközi példa is van, ahol ezt információ kinyerésére, dokumentumok klasszifikálására, összefoglaló készítésére, illetve anonimizálásra használják. Ezekben a közös, hogy mindegyik a jogászi munka hatékonyságát kívánja növelni, illetve a munkavégzést gyorsítaná. Ezen a területen az egyik legnagyobb érdeklődés a bíróságok döntéseit övezi, ugyanis azok jórészt ingyenesen elérhetőek az egyes országokban az Európai Unió területén.
A jogi forráskutatás során azonban az egyes ügyekhez tartozó releváns döntések megtalálása nem minden esetben egyszerű feladat a tapasztalt ügyvédeknek sem. Gyakori probléma ugyanis, hogy az egyes jogi adatbázisok és jogi keresőmotorok egyszerre szűrnek túl és alul. Ez azt jelenti, hogy a bírósági ítéletekre történő keresés során a találati lista sok esetben nem tartalmaz minden releváns dokumentumot, ellenben sok olyan dokumentumot tartalmaz, amik nem a keresett problémához kapcsolódnak, így csak ún. zajt keltenek a keresés során. Az egyik módja a jogi adatbázisok hatékonyságának növelésének, és így a jogi forráskutatás meggyorsításának a bírósági ítéletek csoportosítása bizonyos szempontok szerint.
Bírósági ítéletek pertárgy szerinti kategorizálása
A bírósági ítéletek szövegének megfogalmazása során a magyar döntések esetében a bírók a szöveg elején egy-egy kifejezéssel összefoglalják a per tárgyát, ami tulajdonképpen az eljárás témáját és/vagy célját takarja. A pertárgy nagyon hasznos információ, ha ugyanis egy jogász hasonló témájú ügyeket kíván összegyűjteni, akkor a pertárgy elnevezések tudják orientálni ebben a kutatásban. A bírák azonban nem egy kötött értékkészletből dolgoznak, és semmilyen szabályszerűséget nem használnak abban, hogy milyen pertárgy elnevezést válasszanak, ezért ezek az elnevezések sok esetben nem következetesek, sokszor túl általánosak (pl. a közigazgatási jog területén a „közigazgatási határozat felülvizsgálata” esete), máskor viszont túl specifikusak (pl. 111.234 Ft kártérítés megfizetése), bizonyos esetekben pedig nem tartalmazzák pontosan minden aspektusát az adott ügynek (pl. büntetőjog esetében a „csalás és egyéb bűncselekmények” típusú esetek). Ennek, illetve a sok elírásnak köszönhetően a pertárgy megnevezésekre használt kifejezések folyamatosan növekednek, jelenleg nagyjából 28 000 különböző elnevezés található a magyar bírósági döntésekben, ami a közöttük lévő keresést jelentősen megnehezíti. Éppen ezért hatalmas szükség keletkezett ezek számának, illetve fogalmazásmódbeli különbségeinek csökkentésére.
A bírósági döntések pertárgy szerinti címkézése ugyanis képes a jogi adatbázisok hatékonyságát növelni azáltal, hogy az adatbázis új metaadattal gazdagszik. Ezek a címkék pedig képesek összefűzni a hasonló tartalmú dokumentumokat, amelyek így jobban áttekinthetővé válnak, és ez képes gyorsítani az adatbázist használók, így az ügyvédek munkáját is. Ráadásul ez a címkézés (azaz „labeling”) hosszútávon elősegítheti a jogi eljárások kimenetelének előrejelzését, ami az egyik legfelkapottabb téma a jogi informatikában, és sokan eleve kategorizálási feladatként tekintenek rá, ahogy azt később látni is fogjuk.

A kategorizálás nehézségei
A bírósági határozatok pertárgy szerinti kategorizálása azonban nem egyszerű feladat. A munkánk kezdetekor ugyanis nem állt rendelkezésünkre olyan kategóriarendszer, amit használni tudtunk volna, és így előre felcímkézett nagy számú dokumentumhalmaz sem, amit tanítóadatként fel lehetett volna használni. A felcímkézése ezeknek a többnyire hosszú jogi szövegeknek jogi szerkesztői szakértelmet kíván, nagyon időigényes és monoton, ahogy azt a korábbi cikksorozatunkban is láttuk. A klasszikus aktív tanulási módszerek ezért nem alkalmazhatóak teljeskörűen, ugyanis jelentős mennyiségű emberi munkát igényelne a megfelelő mennyiségű tanítóadat előállítása, hiszen egy jogi szakértő nagyjából 15-20 dokumentumot tud felannotálni egy óra alatt. A projekt során viszont nem volt elegendő időnk arra, hogy a több, mint 200 különböző címkemodellhez előállítsunk megfelelő mennyiségű és minőségű tanítóadatot, ami szükséges az aktív tanuláshoz. Már ugyanis összesen 100 dokumentum bekategorizálása is nagyjából egy-egy munkanapnyi idejét elvitte a fejlesztésben részt vevő két független annotátornak.
Tovább nehezítette a feladatot, hogy a bírósági határozatok kategorizálása egy multi-label problémának tekinthető, ugyanis egy dokumentum több lehetséges pertárgy címkét is felvehet. Ez különösen igaz a büntető jogterület dokumentumaira, amelyeknél általában több bűncselekményt is tárgyalnak egy ügyben. Például akit emberöléssel vádolnak, azt emellett lopással és rablással is vádolhatják ugyanazon esetben.
A jogi szövegek sajátosságai
A különböző adatok és szövegek automatikus kategorizálása nem egy új keletű probléma, a bírósági dokumentumoknak azonban van két sajátossága, ami viszonylag nehezebbé teszi a problémát: az átlagos hosszúsága a dokumentumoknak, valamint az a speciális jogi nyelv, amit használnak. Egy bírósági döntés terjedelme ugyanis általában jelentősen hosszabb, mint azon dokumentumok esetében, amelyeknél általában kategorizáló algoritmust szoktak használni. Ilyen pl. a Reuters (hírügynökségi) és az IMDB (filmes) adatbázisa. A lentebb látható 1. ábra a bírósági határozatok hosszúság szerinti eloszlását mutatja: a dokumentumok hosszúsága a szavakat elválasztó üres karakterek alapján lett számolva úgy, hogy az üres objektumok ki lettek szűrve (tehát pl. amikor több szóköz volt véletlenül egymás után), így a különböző írásjelek nem lettek külön számolva:
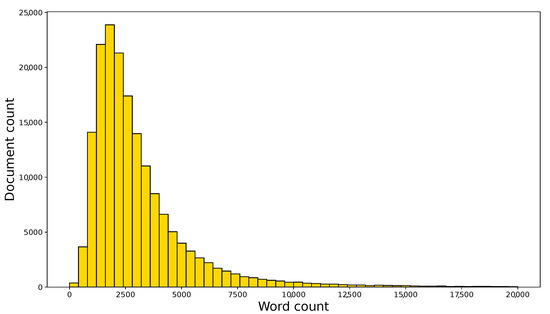
A bírósági határozatok hosszúságának eloszlása a dokumentumokban lévő szavak alapján számolva
Az alábbi táblázat pedig a fent említett adatbázisok és a mi, bírósági dokumentumokból álló adatbázisunk különbségeit mutatja be a kategóriák számossága, a dokumentumok számossága, valamint a dokumentumok hossza alapján. Ebből is látszik, hogy habár az IMDB adatbázis a kategóriák számában, a Reuters adatbázis pedig a dokumentumok számában hasonló a mi adatbázisunkhoz, dokumentumonkénti átlagos szószámban egyik sem összemérhető:

A különböző adatbázisok közötti különbség
Jogi szövegek kategorizálásai
Természetesen a jog területén is voltak már próbálkozások az automatikus klasszifikálás területén. Ezek a korábbi próbálkozások azonban többnyire eltérnek a mi multi-label megközelítésünktől abban, hogy főleg bináris vagy multi-class megoldásokat alkalmaztak. A bináris klasszifikáló azt jelenti, hogy az egyes dokumentumok két típusú kategóriába tartozhatnak csak, de azok valamelyikébe viszont kötelezően. Ilyennek tekinthető például Aletras és kutatótársainak megoldása, amellyel a strasbourgi Emberi Jogok Európai Bíróságának ítéleteinek kimenetelét kívánták előrejelezni, ahol az egyes dokumentumok két kategóriába tartozhattak: vagy megsértett egy Emberi Jogok Európai Nyilatkozatában foglalt cikket vagy nem. A multi-class klasszifikálás pedig abban különbözik a multi-label megközelítéstől, hogy ugyan több kategóriaelembe tartozhat potenciálisan egy dokumentum, de egyszerre csak egy darabba. Ezt a megoldást követi Katz és kutatótársainak megoldása, amivel az Amerikai Egyesült Államok Legfelső Bíróságának ügyeinek kimenetelét igyekeztek megjósolni, és 3 különböző kategóriába besorolni nagyjából két évszázad 240 000 bírói szavazata és 28 000 ügye alapján egy Random Forest klasszifikálót alkalmazva. Ezek a példák is mutatják, hogy az ügyek végkimenetelének előrejelzése és a dokumentumok kategorizálása nem esik annyira távol egymástól.
Összefoglalva tehát a Wolters Kluwer Hungary és a MONTANA Tudásmenedzsment Kft. közös projektje során létrehoztunk egy olyan gép tanuláson alapuló algoritmust, amely képes automatikusan kategorizálni multi-label módon hosszú bírósági szövegeket. Az elkészült algoritmus pedig ezt követően egy úgynevezett digital twinként került telepítésre. Magát az algoritmust a nyílt hozzáférésű Digital-Twin-Distiller keretrendszerünkre alapozva fejlesztettük ki, felhasználva annak különböző pluginjait és természetesnyelv-feldolgozó könyvtárait, hogy felgyorsítsuk a fejlesztés folyamatát. A Digital-Twin-Distiller nyílt hozzáférésű forráskódja elérhető itt: https://github.com/montana-knowledge-management/digital-twin-distiller
Szómagyarázat
![]()
![]()
A kutatásról készült teljes, angol nyelvű tanulmány ingyenesen letölthető innen.
A tanulmány szerzői: