Jogászok vs. algoritmusok II.: a gépi tanulás teljesítményének mérése egy gyakorlati LegalTech probléma esetén
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Jogászok, szerkesztő jogászok és laikusok: a kutatásban eltérő hátterű emberi csoportok mérték össze a tudásukat az algoritmus dokumentumkategorizáló hatékonyságával, teljesítményével szemben.
Cikksorozatunk keretében egy jogi informatikai problémára fókuszálva mutatjuk be, hogy hogyan lehet a gépi tanulás hatékonyságát mérni, milyen eredményeket lehet elérni ezzel a módszerrel, és hogyan segítheti mindez a jogi kutatómunkát. Az első részben olvasható a kutatás kiindulópontja és feltevései, a mai második részben pedig a kutatás módszereit mutatjuk be.
Az érthetőség kedvéért a cikket szómagyarázattal láttuk el, ami az itt előforduló fontosabb, a releváns technológiával kapcsolatos kifejezéseket tartalmazza.
Ahogy az előző cikkben említettük, a legérdekesebb kérdés egy mesterséges intelligenciára épülő projekt esetében, hogy mikor mondhatjuk azt, hogy a gépi tanulás hatékonysága elérte az emberi hatékonyságot, és hogyan lehet beépíteni ezeket a megoldásokat a már létező üzleti dokumentumfeldolgozási folyamatokba. A kutatás ezért a következő öt fő kérdés megválaszolására irányult:
- Mennyi időbe telik az emberi kategorizálónak felcímkézni a teljes adatállományt (ami a kutatás idején a több, mint 170 000 anonimizált bírósági határozatot jelentette), mennyire képes gyorsítani a folyamatot a gépi támogatás?
- Mennyi információt képes kinyerni az emberi kategorizáló a gép segítségével és anélkül?
- Megbízhatóbban teljesítenek-e a gépi tanuláson alapuló algoritmusok az embereknél a jogi dokumentumok kategorizálása esetén?
- Az algoritmusok képesek-e elfedni a különbségeket a jogi szerkesztők és a jogi szakértelemmel nem rendelkező emberek vagy a nem-szerkesztő jogászok között?
- Mekkora az egyetértés a jogi szerkesztők kategorizálása között?
A kutatásban használt dokumentumok
2020. április 1. óta, azaz a korlátozott precedensrendszer magyar jogrendszerbe történő bevezetése óta a korábbinál is hangsúlyosabbá váltak a bírósági határozatok. A bírósági gyakorlat az ügyeket hat különböző ügyszakra vagy jogterületre osztja: büntetőjog, katonai büntetőjog, közigazgatási jog, munkajog, polgári jog és gazdasági jog. A kutatás idején már több, mint 170 000 anonimizált bírósági határozat állt rendelkezésre, amelyek relatíve hosszúak, ugyanis egy átlagos dokumentum 3330 szót tartalmaz. Ugyan talán egyértelmű, de fontos megjegyezni, hogy ezek mind magyar nyelven íródtak, a magyar nyelvnek pedig több olyan sajátossága is van, ami a természetesnyelv-feldolgozásra épülő gépi tanulási feladatokat bonyolultabbá teszik.
Ebből a dokumentumhalmazból 220 határozatot választottunk ki. Ezeket előzetesen a jogi szakértőnk felcímkézte, ami később a kiértékelés alapja lett. A kiválasztásnál fontos szempont volt, hogy a hat jogterületből nagyjából azonos arányban legyenek dokumentumok, illetve, hogy egyenlő arányban legyenek egyszerűbb anyagok, amelyeknél könnyű eldönteni, hogy melyik címke vagy címkék tartoznak rá, valamint bonyolultabb dokumentumok, ahol ez a döntés több időt vesz igénybe. Továbbá fontos szempont volt, hogy hasonló arányban legyenek jelen egycímkés és többcímkés dokumentumok. Végül pedig szempont volt a kiválasztásnál, hogy egyenlő mennyiségben legyenek jelen olyan dokumentumok, amelyek ritka címkéket tartalmaznak, és olyanok, amelyek gyakori címkéket. A kategorizálás során pedig ezeket a dokumentumokat minden résztvevőnek ugyanabban a kötött sorrendben kellett felcímkéznie.
A manuális kategorizálás és a résztvevők háttere
A résztvevőknek 3 óra állt rendelkezésre, hogy annyi dokumentumot felcímkézzenek, amennyit csak tudnak. Ezzel is, illetve a dokumentumok kiválasztásával is ennek a fajta szerkesztői munkának a monotonitását szerettük volna modellezni. 18 résztvevő vett részt a vizsgálatban, akik 3 csoportra oszlottak a kompetenciáik szerint:
- Laikusok: sosem vettek részt formális jogi képzésben eddigi életük során, tehát nem voltak sem jogászhallgatók, valamint nem vettek részt soha jogspecifikus képzésen, csupán a mindennapi életükben találkozhattak a joggal.
- Jogászok: legalább negyedéves joghallgatók vagy jogi diplomával rendelkező személyek.
- Szerkesztő jogászok: a Wolters Kluwer Hungary alkalmazásában álló Jogtár szerkesztők, akik mindennapi feladata a jogi dokumentumok kategorizálása és különböző metaadatokkal történő kiegészítése.
Minden ilyen csoport 6 emberből állt, és ezeket a csoportokat tovább osztottuk két alcsoportra. Az egyik alcsoport az algoritmus alapján előre felcímkézett dokumentumokat kapta meg, és az volt a feladata, hogy eldöntse, jó-e a címkézés, és szükség esetén javítsa azt, míg a másik alcsoport címkézetlenül kapta meg a dokumentumokat, és kézzel kellett kiválasztania hozzá a szerinte megfelelő címkéket.
A résztvevők egy 167 elemből álló címkerendszerből választhatták ki azokat a címkéket, amelyek szerintük a leginkább relevánsak voltak az adott határozatra nézve. A címkerendszert egy jogi szakértő alakította ki, figyelembe véve a magyar jogi dogmatikát, és azt, hogy minden címkéhez megfelelő számú, legalább 20 darab dokumentum tartozzon. Ez azért volt szükséges, mert minden gépi tanuláson alapuló öntanuló modellhez megfelelő mennyiségű tanító adat kell, hogy rendelkezésre álljon.
Az értékelés mérőszámai
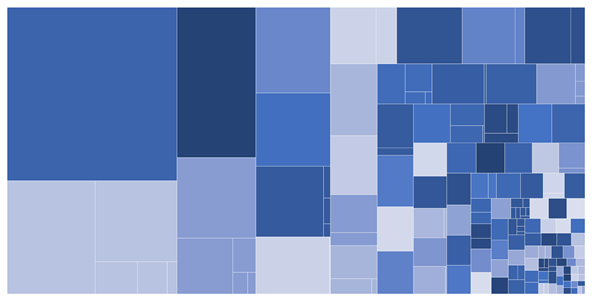
Az ábra a kategóriarendszer egyes címkéinek hozzávetőleges nagyságát mutatja. Minél nagyobb egy négyszög területe, annál több dokumentum tartozik az adott címke alá.
A kategóriarendszer kialakítása során fel kellett ismernünk, hogy az egyes címkékhez tartozó dokumentumok ún. számossága nem azonos, sőt jelentősen eltérhet egymástól. A számosságok 30-tól 30 000-ig terjednek az egyes besorolásoknál, az alábbi ábra az egyes címkék hozzávetőleges nagyságát mutatja be. Minden négyzet nagysága a dokumentumok számosságát és egymáshoz képesti arányát jelzi az egyes címkék esetében. Az információ tartalma az egyes címkéknél fordított arányban áll a címkékhez tartozó dokumentumok számosságával, hiszen minél jobban le tudja szűkíteni a jogi adatbázis felhasználója a dokumentumokat, annál gyorsabban képes megtalálni a számára releváns dokumentumot. Tehát az alacsony számosságú pertárgyak sokkal értékesebbek információs szempontból, mint az általános címkék, amelyekhez akár több ezer dokumentum is tartozik.
Ennek a problémának a kiküszöbölésére bevezettünk egy pontozási rendszert, ami képes kiegyenlíteni ezeket a különbségeket, és jobban méri az egyes címkék információtartalmát. Ez azt jelenti, hogy azok a címkék, amik a teljes dokumentumhalmazon belül több, mint 200 dokumentumon voltak rajta, 1 pontot, amik 50 és 200 dokumentum közötti halmazt tartalmaztak, 5 pontot, amik pedig kevesebb, mint 50 dokumentumon voltak rajta, azok 10 pontot értek. A 220 dokumentum kategorizálása során így a résztvevők potenciálisan összesen 1020 pontot tudtak összegyűjteni. Aki tehát mind az 1020 pontot összegyűjtötte az azt jelenti, hogy minden információtartalmat megtalált a 220 dokumentumban.

A gépi tanulás alapú kategorizálás
Mivel egy bírósági határozat egyszerre több pertárgy alá is tartozhat, ezért a gépi tanulás szemszögéből ez sok különböző bináris klasszifikáló problémát jelent. Ez azt jelenti, hogy az algoritmusnak minden dokumentum esetében minden címke tekintetében el kell döntenie, hogy az releváns-e vagy sem a szöveg alapján. Mivel a pertárgyak átfedik a jogterületeket, tehát egy pertárgy több jogterület esetén is releváns lehet, ezért a 167 címkéhez 229 ilyen bináris klasszifikáló modellt kellett feltanítanunk.
Az automatikus címkéző algoritmus tanításához Support Vector Machine (SVM) megoldást alkalmaztunk, korábbi hasonló példák ugyanis azt mutatták, hogy ez a leghatékonyabb egy klasszifikáló feladat teljesítéséhez. A kis elemszámú címkék esetében pedig szöveg augmentálási megoldásokkal egészítettük ki a módszerünket, ami azt jelenti, hogy mesterséges mintákat hoztunk létre, hogy a tanító adat mennyiségét, és ezáltal a tanítás hatékonyságát megnöveljük. Magát az automatikus címkézést a nyílt hozzáférésű Digital-Twin-Distiller keretrendszerünkben fejlesztettük ki, felhasználva annak különböző pluginjait és természetesnyelv-feldolgozó könyvtárait, hogy felgyorsítsuk a fejlesztés folyamatát.
Az algoritmus feltanításához felhasználtuk a jogi dokumentumok következő sajátosságait: a bírósági határozatokban használt egyes jogi kifejezéseket, illetve a más jogi dokumentumokra (pl. konkrét jogszabályhely) vonatkozó hivatkozásokat, melyek segíthetnek a megfelelő pertárgy vagy pertárgyak megtalálásában. Ehhez TF-IDF (term frequency inverse document frequency) vektorizálót használtunk.
A cikksorozat következő részében bemutatjuk, hogy milyen eredményeket tudtunk megállapítani a kutatás során.
Szómagyarázat
- Természetesnyelv-feldolgozás (Natural Language Processing – NLP): A természetesnyelv-feldolgozás a nyelvészet és a mesterséges intelligencia határterülete, ami az emberi nyelv és a számítógépek kapcsolatával foglalkozik, pontosabban azzal, hogy hogyan képesek a számítógépek feldolgozni és elemezni nagy mennyiségű természetesnyelven alapuló adatokat. Természetesnyelveknek a nyelvészet és a nyelvfilozófia azokat a nyelveket hívja, amelyek organikusan fejlődtek ki az emberi használat és ismétlés során akármilyen tudatos tervezés nélkül. A természetesnyelv-feldolgozás célja, hogy a számítógépek „megértsék” a szöveges dokumentumok tartalmát, különösen annak kontextuális részleteit, és képesek legyenek nagy mennyiségű szöveg elemzésére.
- Support Vector Machine (SVM): az SVM olyan gépi tanulási algoritmus, amit klasszifikálásra és regresszió elemzésre használnak mesterséges intelligencia alapú projektekben. A különböző kategóriákhoz tartozó adatokra képes olyan felületet illeszteni, ami a leghatékonyabban elszeparálja a különböző kategóriába tartozó adatokat. Az SVM a felügyelt gépi tanulási módokhoz tartozik, ami azt jelenti, hogy a tanításhoz szükség van az adatokhoz tartozó címkére egy bizonyos mennyiségű tanítóadaton.
- Term Frequency Inverse Document Frequency (TF-IDF): Ahhoz, hogy a számítógép feldolgozni és elemezni tudja a szöveges dokumentumokat, szükség van arra, hogy numerikus formára hozzuk a szövegeket. Ennek egyik megoldási lehetősége a TF-IDF vektorizálás, egy egyszerű, régóta ismert forma, ami statisztikai alapon súlyozza a dokumentumban előforduló szavakat aszerint, hogy az adott dokumentumban milyen gyakran fordul elő a szó (term frequency), illetve hogy a teljes adathalmaz összességében hány dokumentumban fordul elő ugyanaz a szó (inverse document frequency). Ha egy kifejezés például csak pár dokumentumban fordul elő, akkor az idf értéke magasabb lesz ennek a szónak, mint egy olyan szónak, aminek az előfordulása általánosabb a corpusban.
- Digital-Twin-Distiller: A Digital-Twin-Distiller, a MONTANA Tudásmenedzsment Kft. fejlesztése, egy szövegbányászati feladatok fejlesztési folyamatát támogató nyílt forráskódú platform.


Akiket részletesebben is érdekelnek a kutatás eredményei és a megállapításaink, megtalálhatja a kutatásból készült teljes, angol nyelvű tanulmányunkat itt.
A tanulmány szerzői:
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője
- Üveges István, a Szegedi Tudományegyetem Nyelvtudományi Doktori Iskolájának doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója
- Orosz Tamás PhD, szoftverfejlesztő mérnök
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője