Végre van egy definíciónk a nyílt forráskódú mesterséges intelligenciára
A kutatók hosszú ideje nem értenek egyet abban, hogy mi minősül nyílt forráskódú mesterséges intelligenciának. Egy befolyásos csoport most felajánlott egy választ.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
A Döntvénytáron már a felhasználók is kipróbálhatják a Jogtár legújabb, gépi tanuláson alapuló pertárgy keresőjét. A cikksorozatban bemutatásra kerülnek a fejlesztés részletei és főbb kihívásai.
A technológia fejlődésének és a digitalizáció egyre szélesebb elterjedésének következtében jelentősen megnövekedett az az adatmennyiség, amit az egyes területek szakértőinek a mindennapok során át kell látnia és fel kell dolgoznia. Ezt hívják egyre elterjedtebben az információs infláció problémájának. Ezzel a jelenséggel a hazai jogászoknak is egyre inkább szembe kell néznie, a jogalkotás és a jogalkalmazás folyamatainak felgyorsulásával ugyanis egyre nehezebbé válik az egyes területek mindennapi változásainak nyomonkövetése. A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közös kutatás-fejlesztési együttműködése ezért azt a célt szolgálja, hogy a mesterséges intelligencia előnyeinek felhasználásával a Jogtár felhasználói hatékonyabban találhassák meg a munkájukhoz szükséges jogi dokumentumokat.
Első körben a bírósági határozatok pertárgy szerinti automatikus kategorizálásával foglalkoztunk. Az ezzel kapcsolatos fejlesztésünkről – melynek eredményét már a Jogtár felületén is láthatják és kipróbálhatják a felhasználók – most egy cikksorozat keretében olvashatnak az érdeklődők. Ebben a részben a főbb problémákat vázoljuk fel, a második részben a fejlesztés alapvetőbb módszereit, az utolsó részben pedig a legfontosabb eredményeket mutatjuk be részletesen.
A megoldandó problémák
Napjainkban a fejlett adattárolási módszereknek és a számítógépek teljesítményének fejlődésének köszönhetően, valamint a megváltozott felhasználói szokások miatt is a mindennapokban hatalmas mennyiségű adat jön velünk szemben az életünk során, valamint az egyes tevékenységeinkkel mi magunk is nagy mennyiségű adatot állítunk elő. A digitalizációnak és a technológia fejlődésének köszönhetően tehát az egyes területeken ma változó intenzitással, de a mindennapi munka során nagy mennyiségű, strukturálatlan adathalmazok képződnek. Ezek pedig újfajta kihívások elé állítják azoknak a szakmáknak a képviselőit, ahol fontos a folyamatosan generálódó információk megismerése.
Korábban még ugyanis az volt a kérdés, hogy hol találhatjuk meg a számunkra szükséges információt, melyik könyvtárban, milyen adathordozón vagy melyik nálunk tapasztaltabb kollégánál. A digitalizációnak köszönhetően viszont az információk jelentős része már elérhető vagy legalábbis könnyebben hozzáférhetővé tehető az internet segítségével. Ma sokkal inkább az a probléma, hogy a nagy információs zajban hogyan találjuk meg a számunkra hasznos információt és hogyan szűrjük ki azokat, amik számunkra nem relevánsak. Ezt szokták általánosságban az információs infláció problémájának nevezni.
Hasonlóan ugyanis ahhoz, amikor bizonyos termékeknek megemelkedik az ára, és ezért az egységnyi mennyiségű fizetőeszköz veszít az értékéből, úgy a hirtelen megnövekedő adatmennyiség is értékcsökkentő hatással lehet a megszerezni kívánt információra, ugyanis az adatzajban könnyebben elveszhetnek a számunkra releváns találatok. Így, ahogy a jegybankok kamatemeléssel próbálják a fizetőeszköz értékét megőrizni, az adatszolgáltatóknak is újfajta megoldásokat kell találniuk arra, hogy a náluk meglévő információk a felhasználók számára továbbra is hasonló, vagy lehetőség szerint még nagyobb értékben hozzáférhető legyen. Ehhez tudnak megoldást nyújtani a különböző mesterséges intelligenciára épülő adatfeldolgozási megoldások.
Nincs ez máshogy a jog világában sem. A jogászok, ügyvédek számára ugyanis nagyon fontos, hogy az eléjük kerülő ügy, jogkérdés szempontjából releváns összes jogszabály, illetve joggyakorlat a rendelkezésükre álljon, hogy az ügyfelük számára a lehető legjobb munkát végezhessék – a legkisebb energiabefektetéssel és a legkisebb kockázattal tudjanak hatékonyan fellépni. A jogalkotás és a jogalkalmazás folyamatának felgyorsulása miatt azonban megnövekedett a naponta megszülető adatoknak, például a törvényeknek, rendeleteknek, ítéleteknek a mennyisége, ami még az egyes területekre specializálódott jogászoknak is nehézzé, sokszor lehetetlenné teszi, hogy naprakész legyen minden információval kapcsolatban. A Jogtár felületén például jelenleg több, mint egymillió dokumentum érhető el, amely növekedésének üteme ráadásul folyamatosan bővül. Ezek között a dokumentumok között már most többfajta logikával és mechanizmussal lehet keresni, viszont az újfajta kihívások újfajta megoldásokat igényelnek.
A Wolters Kluwer Hungary szándéka, ahogy eddig is az, hogy a jogász felhasználói számára újfajta innovatív megoldásokat dolgozzon ki a legújabb mesterséges intelligencia eszközökkel az adatbázisában meglévő tudás felhasználásának segítségével. A cél, hogy a felhasználók gyorsabban és könnyebben tudjanak keresni a dokumentumok között, és hatékonyabban megtalálják azokat az információkat, amelyek az egyedi ügyük szempontjából a legrelevánsabbak.
A WK Hungary ezért a MONTANA-val közösen egy kutatás-fejlesztési projektbe kezdett, hogy jogi szakértők, jogi szerkesztők, szoftverfejlesztők és szövegfeldolgozási specialisták együttműködésével a mesterséges intelligencia megoldásokban rejlő lehetőségek felhasználásával a Jogtár adatbázisában meglévő dokumentumok feldolgozását, valamint a felhasználók számára a dokumentumok megtalálását gyorsabbá és költséghatékonyabbá tegye. Az együttműködés első fázisában a bírósági határozatok kereshetőségét helyeztük a fókuszba, ugyanis a jogi forráskutatás, azon belül is a joggyakorlat feltérképezése az a folyamat, ami a jogászok idejét a leginkább lefoglalja, emellett pedig a korlátozott precedensrendszer magyarországi bevezetésével a jogszabályok mellett a jogesetek is egyre fontosabbá válnak a jogászok számára.
A Döntvénytáron belül a Bírósági Határozatok Gyűjteménye (BHGY) a Jogtár adatbázisában jelenleg közel 190.000 különböző bírósági határozatot tartalmaz, ami évente körülbelül 12.000 darab új bírósági határozattal bővül – látható, hogy jelentős mennyiségű adatról van szó önmagában is. A bírósági határozatokon belül első körben a dokumentumok pertárgyanként történő automatikus címkézésével foglalkoztunk.
Az, hogy miért erre esett először a választásunk, annak több oka volt. A fő indokunk az volt, hogy úgy láttuk, ez jelentősen segítheti a Jogtár felhasználók határozatkeresését, ugyanis a pertárgy szerinti szűréssel egy találati listában láthatóak a hasonló témájú dokumentumok, így, ha a szakértő talál egy számára hasznos dokumentumot, akkor az ahhoz hasonló dokumentumok egyszerűen kezelhetővé válnak. Másrészt ez az a tevékenység, ahol a Jogtár jogi szerkesztőinek a munkáját nagy mértékben lehet segíteni, hiszen a bírósági határozatok pertárgy szerinti besorolása nagy mennyiségű munkát igényel, viszont gépi segítséggel lehet csökkenteni a munka emberi erőforrásigényét, így a nagy szakértelemmel rendelkező jogi szerkesztők átállíthatók nagyobb hozzáadott értékű munka elvégzésére. Végül pedig a jogi informatikával foglalkozó nemzetközi szakirodalom alapján az a tapasztalat, hogy az ilyen klasszifikáló, kategorizáló projektek az előfeltételei minden más komolyabb fejlesztésnek, mint például a bírósági ügyek kimeneti predikciója, a hasonlóság, vagy tényállás alapú keresések.
Első lépések: egyszintű konzisztens kategóriarendszer kialakítása
Az első probléma viszont, amivel szembesülnünk kellett, hogy a magyar bírósági határozatok esetében nincs egységes kategóriarendszer, amit következetesen használnának a különböző intézmények. Szemben akár az Európai Unió Bíróságának vagy az Emberi Jogok Európai Bíróságának mindent átfogó kötött tárgyköreivel, a magyar bírósági határozatokkal foglalkozó adatbázisok csak részterületeket lefedő tárgyköröket használnak a legtöbb esetben. Emellett a bírósági határozatokban szereplő leírásban sem használják következetesen a pertárgyak elnevezéseit (pl. Kártérítés vagy Kártérítés megfizetése), ráadásul sok esetben a leírás alapján nem is teljesen beazonosítható a határozat témája (pl. 1.020.345 Ft megfizetése).
Ezért az előző projektünk során azt a megoldást alkalmaztuk, hogy általánosítottuk ezeket az elnevezéseket, és ezek alapján hoztunk létre egy kategóriarendszert, az egyes címkékhez pedig igyekeztünk minél több tanítóadatot szerezni, hogy az algoritmus azok alapján később minél eredményesebben tudja címkézni a bejövő új határozatokat. Ennek a projektnek a részletes eredményeit már korábban több cikksorozatban bemutattuk a Jogászvilág oldalán: Jogászok vs. algoritmusok: a gépi tanulás teljesítményének mérése a gyakorlatban egy LegalTech probléma esetén I., és Hogyan készíts magadnak gépi tanuláson alapuló automatikus címkéző algoritmust? I.
Ezért az előző projekt eredményeibe most részletesen nem megyünk bele, elég csupán annyit kiemelni, hogy a fejlesztés és az azt követő kutatás tapasztalatai alapján az így elkészített első címkéző algoritmus jelentősen volt képes javítani az úgynevezett Throughput and performance metrikákat. Ez azt jelenti, hogy az adott adatállomány, jelen esetben a bírósági határozatok feldolgozásának mennyiségét, és a feldolgozás során kinyert adatok minőségét jelentősen megnövelte.
Amit viszont tapasztaltunk, hogy a kategóriarendszer kidolgozatlansága és a tanítóadatok nem megfelelő tisztasága jelentősen rontotta a címkéző algoritmus teljesítményét. Az egyes címkék (vagyis pertárgyak) esetében ugyanis nem volt egységes az, hogy az egyes kategóriákhoz mennyi dokumentum tartozik. Voltak ugyanis olyan címkék, amikhez nagyon sok, akár tízezres dokumentumhalmaz tartozott, míg másokhoz kevés, tízes nagyságrendű. Ez látszik a lenti ábrán is. Ez nem volt jó egyrészt az algoritmus szempontjából, ugyanis így voltak olyan címkék, amikhez sok tanítóadat volt, más címkékhez viszont kevés, így voltak olyan modellek, amik jól működtek, míg voltak olyanok, amik rosszabbul. Másrészt a későbbi felhasználás szempontjából sem ideális, ugyanis a felhasználók így egyes címkékkel túlságosan leszűrnék a találati listát, míg más címkék gyakorlatilag nem jelentenek releváns szűrést. Végül pedig a tanítóadat minőségének szempontjából sem volt ez ideális, hiszen az általánosabb címkék valószínűleg kevesebb egzakt attribútumot tartalmaztak, amire a gép rá tudott tanulni, ráadásul előfordult az is, hogy két címke között nagy volt az átfedés dokumentumok tekintetében, ami megnehezítette az algoritmus helyzetét, hogy pontosan el tudja határolni egymástól a két kategóriát.
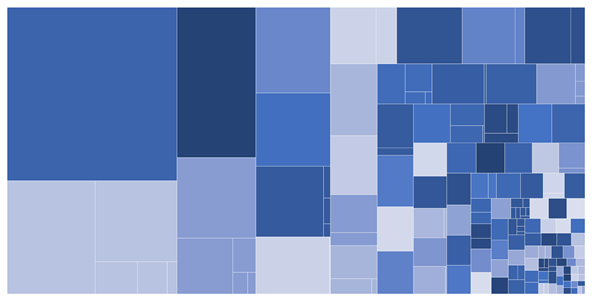
Az ábra a kategóriarendszer egyes címkéinek hozzávetőleges nagyságát mutatja. Minél nagyobb egy négyszög területe, annál több dokumentum tartozik az adott címke alá.
A következő lépés: az algoritmus finomítása, pontosabb szabályrendszer felállítása
Ezért a bírósági határozatok automatikus kategorizálását célul kitűző projekt következő szakaszában a korábbi fejlesztések tapasztalatainak felhasználásával a kategóriarendszer szofisztikáltabb kialakításával és a tanítóadat minőségének javításával javítottuk a címkézés hatékonyságát, vagyis a pertárgy alapú kategorizálását. Ehhez kialakítottunk egy komplex módszertant, melyről részletesen a következő cikkben olvashatnak. Annyit azonban elárulhatunk, hogy egy hierarchikus címkerendszert hoztunk létre, mert a tapasztalatok alapján azt láttuk, hogy a hierarchikusság lefedi a jogi logika alapvető sajátszerűségeit, vagyis azt, hogy a legtöbb jogi kategória általában besorolódik valamilyen más nagyobb tárgykörbe is, valamint az adathalmaz statisztikai és nyelvi megközelítéséhez is közelebb áll, mint a korábban alkalmazott egyszintű kategóriarendszer.
Ez a bírósági határozatokat pertárgyak alapján hierarchikus címkerendszer szerint automatikusan kategorizáló gépi tanulási projektjéről szóló cikksorozat első része. A következő részben bemutatjuk a címkerendszer kialakítása során alkalmazott módszertan egyes lépéseit részletesen, az utolsó részben pedig az így előállított felügyelt tanításon alapuló gépi modellek teljesítményének főbb eredményeit.
![]()
![]()
A cikk szerzői: