A jogi kivonatkészítő algoritmus – Eredmények III.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Mi köze a napozó szürke macskának a bírósági határozatokhoz, a nyelvi modellekhez és a gépi tanuláshoz? Mire jutott a fejlesztői csapat az extraktív jogi kivonatok kapcsán? A cikksorozat befejező része ismerteti az eredményeket.
A bírósági határozatok végigolvasása és megértése a legtöbb esetben sok időt és munkát vesz igénybe, mert az átlagosnál hosszabb és bonyolultabb szövegekről van szó. Viszont ez a munkafolyamat elengedhetetlen a jogászok életében azért, hogy az ügyfeleik számára a legjobban lássák el a munkát. Sok esetben viszont feleslegesen olvasnak el hosszú bírósági határozatokat, ha a keresőjük nem támogatja azt, hogy hamar el tudják dönteni, hogy az adott dokumentum releváns-e a számukra. Ez utóbbi sokszor csak azután tudatosul bennük, hogy végigolvasták a határozatot, vagy legalábbis egy nagy részét, és feleslegesen töltöttek el időt ezzel. Ehhez nyújt segítséget, ha a szöveg elején látnak egy rövid kivonatot, ami segíti a gyors döntést.
A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közösen egy olyan automatikus kivonatkészítő algoritmust fejlesztett, ami képes kiemelni a 4 legrelevánsabb mondatot az egyes bírósági határozatok szövegéből, és ami már elérhető a Jogtár felületén a felhasználók számára is. Ez a fejlesztést bemutató cikksorozat utolsó része, amely a fejlesztési folyamat során használt modellek kiértékelését és eredményeit mutatja be.
A bírósági határozatok szövegeiből automatikusan kivonatot készítő algoritmus fejlesztésének egyik legfontosabb része a kivonat minőségét befolyásoló, a cikksorozat előző részében bemutatott módszerek hatásának megmérése volt, tehát az, hogy mi az az eljárás, ami a bírósági határozatokból a legrelevánsabb mondatokat emeli ki kivonatként. Ezek a minőséget befolyásoló tényezők:
- a vektorizálási formák,
- a kiválasztási és rangsorolási megoldások,
- a mondatszám meghatározás és a
- nem releváns szövegegységek kiszűrése a dokumentumokból.
A kiértékelés során több fontos szempontot is figyelembe kellett venni. Egyrészt azt, hogy ezen különböző, a kivonat minőségét befolyásoló tényezők eredményeit nem egyesével kellett megmérni, hanem egymással kölcsönhatásban, egymással kombinálva. Másrészt pedig azt, hogy a kivonatkészítés meglehetősen szubjektív műfaj, két külön ember nagy eséllyel különböző mondatokat fog fontosnak tartani kiemelni ugyanabból a szövegből. Ezért megfelelő módszert és megfelelő kiértékelési metrikákat kellett választani az algoritmus eredményeinek kiértékeléséhez.
Az egyes módszerek kiértékeléséhez a Wolters Kluwer Hungary Kft. szerkesztői csapata 150 bírósági határozat esetében elkészítette a dokumentumok kivonatát kézzel. Arra kértük őket, hogy az egyes határozatokból válasszák ki azokat a mondatokat, amelyekről úgy gondolják, hogy az ügy szempontjából fontosak és segíthetnek a határozatot nem ismerő felhasználónak eldönteni, hogy az számára releváns-e vagy sem.
A kézi kivonatok elkészítését követően ezeket a mondatokat kezeltük “ideális kivonat” mondatokként, a továbbiakban pedig azt mértük, hogy az algoritmus által a különböző módszerek felhasználásával kiválasztott mondatok mennyire állnak ehhez közel. A 150 bírósági határozatot úgy választottuk ki, hogy abból 140 darab EBH (elvi bírósági határozat), 10 darab pedig EBD (elvi bírósági döntés) legyen azért, mert ezekhez a dokumentumokhoz már tartoznak olyan kézzel írt absztraktív összefoglalók, amelyek a határozatok lényegét akarják megragadni és amelyeket össze tudtunk mérni a kézzel előállított ideális kivonatokkal és az algoritmus által készített extractokkal. Ezt követően a megfelelő kiértékelési metrikákat kellett kiválasztanunk.
Kiértékelési metrikák
Ahogy említettük, a kivonatkészítés erősen szubjektív műfaj, mindenki mást fog megfelelő kivonatnak értékelni, mégis elengedhetetlen, hogy az algoritmus által generált kivonatok minőségét és perfomanciáját össze tudjuk mérni az ideálisnak kezelt kézi kivonatokkal. Ehhez az egyik lehetőség az úgynevezett ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrikák használata.
Ezeknek a mérőszámoknak a lényege, hogy képesek automatikusan kiértékelni a gép által generált kivonatokat a kézi kivonatokhoz képest úgy, hogy megvizsgálják a szavak közös előfordulásait. Ezek között a metrikák között is az egyik legelterjedtebb eljárás a ROUGE-N, amelynél N helyére behelyettesíthetünk bármilyen számot attól függően, hogy hány egymás utáni szó közös előfordulását szeretnénk vizsgálni.
A ROUGE-1 például egyes szavak előfordulását vizsgálja a kézi és a generált kivonat-mondatokban, a ROUGE-2 szópárokat vizsgál, a ROUGE-3 egymást követő 3 szót néz, és így tovább. Mi az algoritmus kiértékeléséhez alapvetően a ROUGE-1 és a ROUGE-2 metrikákat használtuk, tehát azt vizsgáltuk, hogy az egyes szavak, illetve szópárok mennyire fedik egymást a kézzel előállított és az algoritmus által készített kivonatban.
Mindkét esetben meghatározható a kivonatolás eredményének pontosság (precision) és fedés (recall) értéke. A pontosság esetében arról kapunk visszajelzést, hogy a gép által az összefoglalóba beválogatott szavakból mennyi azok aránya, amelyek helyesen kerültek be az összefoglalóba, a fedés pedig azt mutatja meg, hogy a megtalálandó szavak közül mekkora arányban adta azokat vissza az algoritmus.
Tekintsük meg ezeket egy példán keresztül:
- Elvárt kimenet: A macska egy kanapén fekszik.
- Generált kimenet: A macska és egy kutya.
Eredmények: ebben a példában a ROUGE-1 metrika alapján az algoritmus pontossága 3/5, tehát 60 %-os lenne, hisz a generált kimenetben összesen 5 szó van, amiből 3 helyes (“A”, “macska”, “egy”). A ROUGE-2 metrika alapján pedig ¼, tehát 25 %, hisz 4 szópár található a generált mondatban, amiből 1 darab helyes („A macska”). A ROUGE-1 és ROUGE-2 metrikák esetében így alakult az egyes vizsgált módszerek eredményének F1 értéke, amely a pontosság és a fedés értékek harmonikus közepe:
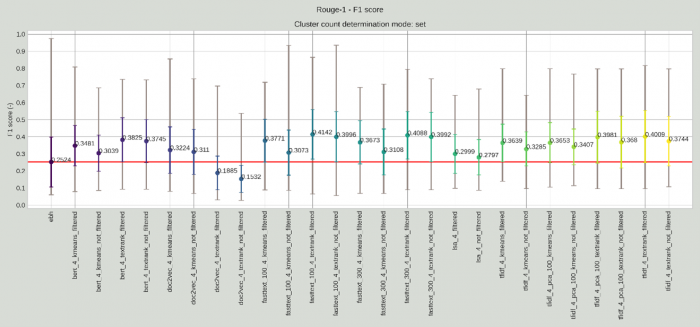
A fixen beállított 4 mondatos extraktokat gyártó automatikus kivonatoló modellek F1 értékei a ROUGE-1 metrika szerint. A függőleges oszlopon látszódnak az egyes modellek F1 értékei, azok minimális, maximális értéke, valamint átlaga és szórása. A vízszintes tengelyen az egyes megoldások attribútumai láthatóak, amiknek a jelentését lentebb fejtünk ki bővebben. A piros vonal az EBH-k kivonatainak a teljesítményének átlagát mutatja.
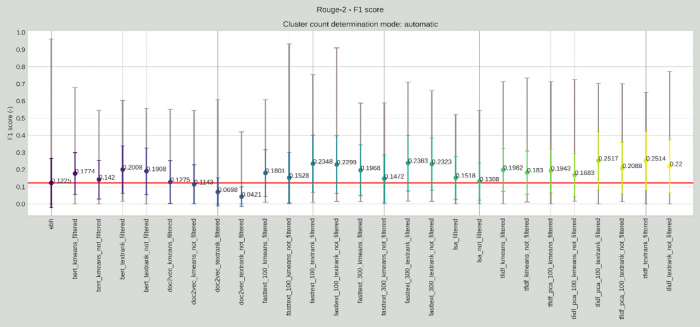
Az algoritmus által automatikus választott mondatszámú kivonatok értékei az egyes modellek működésének hatékonysága szerint a kézi kivonatokhoz mér ROUGE-2 metrika szerint.
Ezek az ábrák elsőre bonyolultnak és ijesztőnek tűnnek, de egyáltalán nem kell megijedni tőlük. A függőleges tengelyen látszódnak az F1 értékek, amelyek 0 és 1 közötti értéket tudnak felvenni, ahol 1 a lehető legpontosabb átfedést jelentené a kivonatok között, a 0 pedig azt jelenti, hogy a két kivonat teljesen más.
A vízszintes tengelyen pedig az egyes megoldások láthatóak, első helyen az EBH-k és EBD-k elején szereplő rövid összefoglalók hasonlósága a WK jogász szerkesztői által kézzel előállított kivonatokhoz, majd az egyes gépi megoldások az előző cikkben bemutatott tényezők kombinációjában. Ezeknek az elnevezése több tagból áll össze: az első jelzi, hogy milyen vektorizálási mód lett használva, majd, hogy milyen klaszterezési vagy rangsorolási módszer lett kiválasztva, végül pedig, hogy lettek-e a szövegegységek szűrve vagy nem.
Az ábrák tetején pedig a mondatszámok kiválasztási módja szerepel, amely lehet set (tehát kézzel beállított 4 mondat), automatic (tehát automatikus a K-Means algoritmus segítségével), illetve empirical (tehát a szöveg hossza szerint változó, pontosabban a kézzel annotált eredményekre illesztett egyenes alapján meghatározott), ahogyan azt az előző cikkben bemutattuk.
Az egyes megoldásoknál pedig látszódnak a dokumentumok kivonat-mondataira kiértékelt minimális és maximális értékek, valamint ezek szórása és átlaga. A piros vonal pedig az EBH/EBD esetében készített kivonatok eredményeit jelzi annak érdekében, hogy könnyebben összehasonlíthatóvá váljon, hogy mely gépi eredmények haladják meg azok minőségét és melyek nem. Itt most a ROUGE-1 metrikához a kézzel beállított mondatszám értékeit, a ROUGE-2 metrikához pedig az automatikus mondatszám kiválasztás értékeit bemutató ábrát tettük be. Természetesen mindegyik mondatszám kiválasztási forma esetében elkészült a kiértékelés mindegyik metrikára, de ide most csak párat választunk ki, részletesebben egy tudományos publikációban fogjuk ezeket bemutatni.
A ROUGE-N metrika mellett a másik elterjedt ROUGE megoldás az úgynevezett ROUGE-L metrika, amely abban különbözik az előzőkben bemutatottól, hogy a kiértékelés alapját nem az egyes szavak vagy az egymás utáni szópárok stb. átfedése jelenti, hanem az úgynevezett leghosszabb közös részszekvencia (Longest Common Subsequence, LCS). Ez a mondatoknak azon szóhalmaza, amelyek (akár megszakításokkal, de) azonos sorrendben fordulnak elő mind a generált, mind pedig az elvárt kimenetben. Például:
- Elvárt kimenet: Egy perccel ezelőtt a napozó szürke macska felém
- Generált kimenet: A szőnyegen álmosan napozó, szürke macska felém fordította a fejét egy perccel ezelőtt.
- LCS: a napozó szürke macska felém
Nyilván minél hosszabb ez a leghosszabb közös részszekvencia a kézi kivonat és az algoritmus által készített kivonat között, annál pontosabb az algoritmus működése. A ROUGE-L metrikára nézve a következő eredményeket kaptuk a kézzel beállított 4 mondatos megoldások példáin szemléltetve:
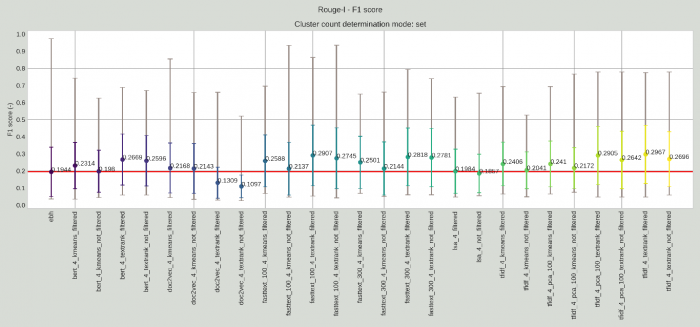
ROUGE-L metrika értékei, amely az egyes kivonatkészítő megoldások minőségét méri, fix, 4 mondatszámú kivonatok esetén.
A ROUGE metrikák nagy hátránya viszont, hogy túlságosan az egyes szavak és kifejezések azonosságát és átfedését veszik figyelembe, és azt nem, ha két kivonat jelentéstartalom szerinti azonossága magas, de nem azonos szavakkal vagy a szavak nem azonos szórendjével van kifejezve. Például, ha az elvárt kivonat mondat egy határozatban az lenne, hogy “A bíróság a további felperesi eljárási jogszabálysértési hivatkozások vizsgálata alapján viszont arra a meggyőződésre jutott, hogy az alperes támadott közigazgatási határozata sérti az Ákr. 81. § (1) bekezdésében foglaltakat, ezért az érdemi felülvizsgálatra alkalmatlan”, viszont a határozat egy későbbi részében ezt újra úgy fogalmazzák meg, hogy “Nem megfelelő a felülvizsgálati indítvány, mert az alperes döntése nem felel meg az Ákr. 81.§ (1) bekezdésének”, és az algoritmus ezt a mondatot emeli ki, akkor a ROUGE kiértékelések alapján nem lenne optimális a működés, a szavak átfedése és sorrendje alacsony a két mondat esetén, viszont érezzük, hogy jelentésben azért nem állnak olyan távol egymástól ezek a mondatok, ezért nem olyan nagy probléma, ha az algoritmus ezeket felcseréli.
Mindez az ábrákon is látszik, hiszen a legtöbb esetben még a 0,5-ös értéket sem sikerült egyik megoldásnak sem elérnie. Ez utóbbi a magyar nyelv szórendbeli rugalmassága miatt különösen gondot okozhat és így a ROUGE-2 és a ROUGE-L értékeket jelentősen le tudja rontani. Ennek a problémának a kiküszöböléséhez nyújtanak segítséget a jelentéstartalmat is figyelembe vevő metrikák.
Ezek közül két megoldást használtunk; a FastText és a BERT szerinti koszinusz távolságot. Ezek lényege, hogy a szövegeket vektorrá alakítják, oly módon, hogyha két vektor hasonló irányba mutat, akkor jelentéstartalmuk is nagyban megegyező. Ehhez először mondatokra bontottuk a kézi kivonatokat, valamint a gépi kivonatokat, majd az egyes mondatokhoz kiszámoltuk ezek vektorreprezentációját FastText illetve BERT módszerekkel. A mondatok vektorait ezután átlagoltuk, így képezve a kivonatoknak a vektorát. A gép általi kivonat, illetve az emberek által készített kivonat vektorainak koszinusz távolságát számoltuk ki minden egyes példa kivonatra, majd szintén kiszámoltuk ezek átlagát, szórását, minimumát és maximumát. Ezáltal a fenti példa esetén például kezelni tudtuk azt, hogy ugyan a szavak átfedése és a szórend eléggé különbözik egymástól az elvárt kivonatban és a generált kivonatban, viszont jelentéstanilag nem különbözik egymástól a két mondat annyira. A Fasttext kiértékeléssel a következő módon alakulnak az eredmények:
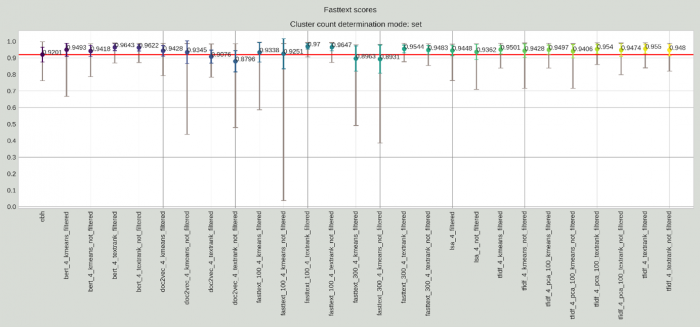
Az egyes kivonatkészítő módszerek Fasttext értékei kézzel beállított, 4 mondatok esetén
Ezek a megközelítések már sokkal jobb eredményeket adnak. Ez természetesen nem csak önmagában azért jó, mert jobbnak néznek ki az eredmények, hanem azért is, mert ezek a metrikák segítenek abban, hogy olyan kivonatokat készítsünk az algoritmus segítségével, amelyek jelentésben a legközelebb állnak az elvárt kivonatokhoz, azaz hasznosabbak a jogászoknak az így olvasható extractok.
Ezeket és a ROUGE metrikákat felhasználva pedig sorrendbe tudjuk állítani, hogy az egyes megoldások a bírósági határozatok esetén milyen minőségű kivonatot képesek készíteni. Jól látszik például, hogy sok megoldás a legtöbb mérőszám esetében meghaladta az EBH-EBD-k által kézzel készített összefoglalók teljesítményét. Fontos megjegyezni, hogy ez nem azt jelenti, hogy a gép által kiválogatott mondatokból képzett kivonatok jobb minőségűek lennének, mint a kézzel “írottak”, hiszen a két kivonat alapvető célja más: az EBH/EBD-k összefoglalóinak lényege egy, a jogi szempontból releváns, amolyan jogi konklúzió levonása, szemben az extraktokkal, amelyek az ügyről egy általánosabb tájékozódást céloznak és tesznek lehetővé. Azt viszont jelenti, hogy a gépi extractok közelebbinek bizonyultak a kézzel kiválogatott mondatokhoz, mint az EBH/EBD elején levő összefoglalók.
Sok megoldást el tudtunk vetni, mert a legtöbb metrikában nem mutatott jó eredményeket. Viszont az is látszik, hogy a legjobban teljesítő megoldásokat csak egy hajszál választja el egymástól, illetve sok esetben különbözik, hogy melyik mérés alapján melyik megoldás végez előrébb. Ezért ezeken az automatikus kiértékeléseken felül még egy megközelítést be kellett vetnünk annak érdekében, hogy eldönthessük, melyik a legjobban teljesítő modell.
Végleges validáció
Annak érdekében, hogy megállapíthassuk, hogy a felhasználhatónak tűnő megoldások közül melyik a legjobb és melyik legyen az az egy, amelyiket kiválasztunk végül a teljes adathalmaz kivonatolásához, a legjobb 4 megoldást jelöltük ki, amelyek az automatikus kiértékelés alapján a legjobban teljesítettek, és elkészítettük 56 új dokumentum extraktját. Ezt követően a 4 legjobb megoldás kivonatait és az eredeti szöveget odaadtuk a WK jogi szerkesztőinek, hogy az egyes kivonatokat értékeljék 1-től 5-ig aszerint, hogy mennyire elfogadható a minőségük. Természetesen a szerkesztőknek nem árultuk el, hogy a gépi kiértékelés alapján hogyan végeztek ezek a megoldások, hogy ne befolyásoljuk őket. A kiválasztott 4 legjobb megoldás egyébként a következő volt:
- 100 dimenziós FastText 4 mondattal,
- 300 dimenziós FastText 4 mondattal,
- BERT 4 mondattal,
- TF-IDF automatikus mondatszám-meghatározással.
Emellett mindegyik megoldás TextRank megoldást alkalmazott, illetve kiszűrtük a kivonat számára eleve nem releváns szövegegységeket, mert azt tapasztaltuk, hogy ezek a tényezők általánosságban jobb eredményt szavatolnak. Az egyes megoldások kézi validációjának eredményeit a következő táblázatban foglaltuk össze. Az egyes sorokban az egyes modellek eredményei láthatóak aszerint, hogy az oszlopokban szereplő értéket hányszor kapták meg a szerkesztőktől a különböző dokumentumokra, majd végül az eredmények átlaga szerepel.
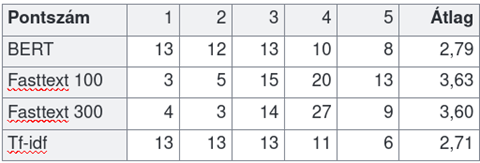
A gépi kiértékelések során 4 legjobban teljesített modell eredményei a kézi validáció során, ahol 1-től 5-ig lehetett értékelni az egyes eredményeket.
Ebből arra a következtetésre jutottunk, hogy bár nem sokkal, de a Fasttext 100-as modell teljesített a legjobban. A megközelítések közötti sorrend egyébként ugyanaz lett, mint a gépi metrikák esetében. Ez megerősíti azt, hogy a kiértékeléshez használt mérési módszerek megfelelően lettek kiválasztva. Így végül a Fasttext 100 szerint vektorizáló, Textrank algoritmust használó, fixen 4 mondatot kiválasztó és a nem releváns szövegegységeket kiszűrő modell lett kiválasztva, és jelenleg a Jogtár felületén ez az a megoldás, ami az összes bírósági határozatból kiválogatja a legrelevánsabb mondatokat.
Összefoglalás és további fejlesztési irányok
A fentiek alapján, és az előző cikkekben bemutatott módszerek és lépések segítségével elkészült az algoritmus, amely automatikusan, szerkesztői beavatkozás nélkül elkészíti a bírósági határozatok extraktív kivonatait. A kiértékelési metrikák és a validációs szempontrendszerek alapján ezek a kivonatok Fasttext algoritmussal, Textrank megoldással készülő négy mondatos kivonatok minden dokumentum esetében, amelyek a Jogtár felületén már el is érhetőek a felhasználók számára. A mérések alapján ezzel a megoldással sikerült elég közel kerülni a szerkesztők által az egyes dokumentumok esetében ideálisnak tartott kivonatok létrehozásához, sőt, sikerült jelentéstartalmat tekintve jobban megközelíteni a kézi kivonatok szintjét, mint az EBH-k, illetve EBD-k elején található pár mondatos összefoglalók esetében.
A fejlesztés azonban ezzel nem teljesen ért még véget. A Jogtár felületén elérhető kivonatok ugyanis értékelhetőek a felhasználók által és a szöveges visszajelzéseket is nagyon szívesen vesszük annak érdekében, hogy a kivonatok minőségét tovább tudjuk javítani. A további közvetett haszna a fejlesztésnek a dokumentumokhoz tartozó egyes kivonatokon túl az is, hogy sikerült egy módszertant kidolgoznunk, amivel nyelv- és szakterület függetlenül képesek vagyunk egy adott szövegállomány esetében megállapítani, hogy mi az a módszer, amivel a leghatékonyabban készíthető összefoglaló. A továbbiakban ezt a módszertant is szeretnénk továbbfejleszteni.
Ez az írás a Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közös, automatikus összefoglalót készítő algoritmusának fejlesztését bemutató cikksorozatának harmadik, egyben utolsó része. Az első részben bemutattuk az automatikus kivonatokkal megoldani szánt problémákat, valamint az automatikus összefoglaló készítő algoritmusok típusait, a második részben pedig az egyes extraktív kivonatok minőségét befolyásoló tényezőket.


A cikk szerzői:
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője
- Üveges István, a Szegedi Tudományegyetem Nyelvtudományi Doktori Iskolájának doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója
- Fülöp Anna, a Wolters Kluwer Hungary Kft. szerkesztőségi főmunkatársa
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője