Az ítélet kiegészítése
Az ítélet kiegészítésének hivatalból csak akkor van helye, ha a bíróság érdemi döntésében nem rendelkezett olyan kérdésről, amelyről a jogszabály értelmében hivatalból kötelező – a Kúria eseti döntése.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
Az új automatikus kivonatkészítő algoritmus képes kiemelni a releváns mondatokat a bírósági határozatokból. A fejlesztés során számos tényezőt kellett figyelembe venni, hogy a kivonatok minősége optimális legyen.
Az automatikus összefoglaló készítő algoritmusok képesek lerövidíteni a szövegeket és megadott szempontrendszerek szerint kiemelni a legfontosabb tartalmi elemeket. Ez jelentősen tudja támogatni a jogászok munkáját, akiknek visszatérő feladata, hogy az átlagosnál hosszabb és bonyolultabb szövegeket kell feldolgozniuk és megérteniük napi szinten. Ehhez tudnak segítséget nyújtani az ún. extractok, amivel a szakemberek gyorsabban el tudják dönteni egyes dokumentumokról, hogy számukra relevánsak-e.
A Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közösen egy olyan automatikus kivonatkészítő algoritmust fejlesztett, ami képes kiemelni a 4 legrelevánsabb mondatot az egyes bírósági határozatok szövegéből, és ami már elérhető a Jogtár felületén a felhasználók számára is. Ez a cikksorozat a fejlesztés egyes lépéseit és az algoritmus eredményeit mutatja be.
Ahogy azt az előző részében is bemutattuk, az automatikus kivonatkészítő algoritmus fejlesztése egy nem-felügyelt tanításon alapuló gépi tanulási feladat, ami azt jelenti, hogy nincs szükség címkézett tanítóadatra a fejlesztés megkezdéséhez, hanem az algoritmus képes a szöveg belső szabályszerűségének felismerésével csoportosítani a mondatokat, és kiválasztani a kivonat szempontjából legrelevánsabbakat. Ez viszont nem jelenti azt, hogy hátradőlhetünk és a gép megcsinál helyettünk mindent. Számos olyan tényező van ugyanis, amely képes befolyásolni a kivonatok minőségét és emberi értékelését. A legfontosabb ezek közül a megfelelő vektorreprezentációs forma, a mondatokat csoportosító vagy rangsoroló megoldás kiválasztása, az ideális mondatszám meghatározása, valamint a nem releváns szövegegységek kiszűrése. Ebben a cikkben az egyes tényezőkhöz tartozó megoldásokat mutatjuk be részletesen.
Vektorizálási formák
A vektorizálás minden szövegfeldolgozási folyamat első lépései közé tartozik és lényege, hogy ahhoz, hogy a számítógép feldolgozni és elemezni tudja a szöveges dokumentumokat, szükség van arra, hogy numerikus formára hozzuk a szövegeket. Viszont a különböző vektorizálások eltérő előnyökkel és hátrányokkal bírnak, így a megfelelő vektorreprezentációs forma megválasztása kulcsfontosságú minden gépi tanulási projekt esetében. A használható megoldások köre elég sokrétű az egyszerűbb szózsák formáktól kezdve a bonyolultabb neurális hálókon alapuló megoldásokig. A fejlesztés során mi négy különböző megoldást próbáltunk ki és mértünk össze egymással: a TF-IDF, a Doc2Vec, a FastText és a BERT vektorizálásokat. A továbbiakban ezeket a megközelítéséket mutatjuk be részletesen.
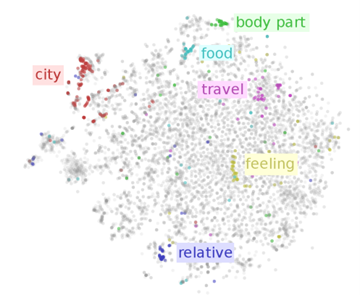
A példa egy szövegállomány szavainak vektorizálását mutatja 2 dimenziós térre redukálva. A képen jól látszik, hogy a vektorizálási módszer bizonyos esetekben képes volt a szemantikailag összetartozó szavakat egymáshoz közel helyezni a térben. Forrás: https://www.ruder.io/word-embeddings-1
A TF-IDF, vagyis a Term Frequency – Inverse Document Frequency egy régóta ismert forma, ami statisztikai alapon súlyozza a dokumentumban előforduló szavakat aszerint, hogy az adott dokumentumban milyen gyakran fordul elő a szó (term frequency), illetve, hogy a teljes adathalmaz összességében hány dokumentumban fordul elő ugyanaz a szó (inverse document frequency). Ha egy kifejezés például csak pár dokumentumban fordul elő, akkor az IDF értéke magasabb lesz, mint egy olyan szónak, aminek az előfordulása általánosabb a korpuszban, azaz a teljes szövegállományban.
A Doc2Vec ezzel szemben a Word2Vec vektorizációs megoldás továbbfejlesztése, amely numerikus formára hozza az egyes szövegegységeket azáltal, hogy a szóreprezentációs vektorokból készít egy szövegre jellemző vektort, és ezáltal képes leképezni egy szövegegység jelentéstartalmát. Jelen esetben a mondatokból képeztünk azok jelentéstartalmát lefedő vektorokat.
A Word2Vec olyan szóreprezentációt biztosít, amely leképezi a szavak jelentéstartalmát, tehát két hasonló jelentésű szó nagyjából ugyanabba az irányba mutató vektorként jelenik meg. A FastText ugyanezen az elven működik, a legfőbb különbség, hogy a Word2Vec csak szavakra, míg a FastText szótöredékekre is képes vektorreprezentációt biztosítani. Ezeket a modelleket felügyelet nélkül tanítják egy nagyobb szövegkorpuszon, kihasználva, hogy a hasonló kontextusban előforduló szavak hasonló jelentéssel is bírnak.
Végül pedig a BERT, amely a többihez képest egy viszonylag újabb megoldás és abban különbözik a korábban használt vektorizálási módszerektől, hogy képes többek között a kontextust, szórendet is figyelembe vevő dokumentum- illetve szószintű vektorforma előállítására is, amelyek rendkívül jól képesek megragadni az egyes szövegek jelentéstartalmát. Remekül alkalmazható a legtöbb számítógépes szövegfeldolgozási feladat esetében például névelem-felismerésre is, de egy fontos limitációval rendelkezik: alapvetően csak rövidebb, legfeljebb 512 token hosszú szövegekre alkalmazhatók egyszerűen, bár ezen a területen folyamatosan fejlesztéseket és javításokat végeznek, hogy képes legyen feldolgozni a hosszabb szövegeket is. A tokenek olyan összefüggő karaktersorok a szövegben, amelyeket jelentéstani egységekként lehet kezelni. Ezek általában egy-egy szót jelentenek, de sok esetben csak szótöredékek. Általában 4-5 karakter szokott egy tokent jelenteni egy szövegben, tehát 512 token körülbelül 400 szó. A legmodernebb természetesnyelv-feldolgozó eszközök, mint például az olyan nagy nyelvi modellek, mint a BERT vagy a GPT, amelyre a Chat-GPT megoldás is épül, már nem a szavakat veszik alapegységnek, hanem ezeket a tokeneket, mert rugalmasabb szövegkezelést tesznek lehetővé például a ritka, vagy összetett szavak esetében.
Kiválasztási és rangsorolási megoldások
A vektorizálási formákon túl a másik fontos szempont, aminek a hatását meg kellett mérnünk a kivonatok minőségére nézve az volt, hogy a különböző nem-felügyelt tanításon alapuló megoldások közül melyik az, ami a legpontosabb kivonatot generálja. Ezeket a megoldásokat megkülönböztethetjük egymástól aszerint, hogy klaszterezésen, topik modellezésen vagy rangsoroláson alapuló megoldásról beszélünk. A klaszterezés és a topik modellezés tulajdonképpen nem más, mint egy adathalmaz automatikus csoportosítása akármilyen előzetesen tanított modell nélkül, csupán az adathalmazban rejlő belső szabályszerűségek felhasználásával. A klaszterezés célja (ha mondatokról beszélünk, márpedig a kivonatkészítéskor mondatokat vettünk alapegységként), hogy az egy klaszterbe tartozó mondatok a lehető leginkább hasonlók, míg a különböző klaszterekbe tartozók a lehető leginkább eltérők legyenek egymáshoz képest, a különbözőség és hasonlóság mérése pedig kellően precíz legyen. A topik modellezés ehhez nagyon hasonló, a lényege, hogy képes felfedezni az absztrakt témaköröket a szövegeken belül, és az azokat legjobban reprezentáló szövegegységeket, jelen esetben a mondatokat. A fejlesztés során egy klaszterezésen alapuló megoldást, a K-Means klaszterezést és egy topik modellezésen alapuló eljárást a Látens Szemantikus Analízist (Latent Semantic Analysis, LSA) próbáltunk ki.
A K-Means klaszterezés az egyik legelső kifejlesztett és leggyakrabban használt ilyen típusú megoldás, amelynek a lényege, hogy az algoritmus képes akár megadott számú, akár bizonyos beállítások segítségével a dokumentumban előforduló ideális számú témakör szerint csoportosítani a mondatokat, és ezt követően az egyes témakörök esetében a klaszterek középpontjához legközelebb álló, tehát az adott témát a legjobban jellemző mondatokat kiválasztani. Ez azt jelenti, hogy akár mi is meghatározhatjuk, hogy hány témakörre ossza fel a dokumentumokat az algoritmus, de arra is megkérhetjük, hogy becsülje meg számunkra, hogy az egyes dokumentumoknál mennyit tart ideálisnak, majd megválaszthatjuk, hogy az egyes témákból 1, 2 vagy akár több mondatot szeretnénk viszontlátni attól függően, hogy mennyire részletes kivonatot szeretnénk kapni. (Az ideális mondatszám meghatározásról a következő alfejezetben fogunk részletesen írni).
Az LSA egy olyan természetesnyelv-feldolgozási módszer, amely képes elemezni a dokumentumok és a bennük található szavak, kifejezések közötti kapcsolatokat. Ehhez szinguláris felbontást, egy matematikai technikát használ, hogy rejtett kapcsolatokat találjon a kifejezések és a szövegben előforduló fogalmak, témakörök között. A szinguláris felbontás lényege, hogy képes leredukálni a szöveget reprezentáló mátrix méretét. Az LSA segítségével egy korpuszban több látens témakör fedezhető fel, és meghatározható, hogy az egyes dokumentumokban milyen a topikok részaránya. A kivonatolás során az egyes témaköröket legjobban reprezentáló mondatokat választottuk ki.
A rangsorolási megoldások ezzel szemben nem témakörökre osztják az egyes szövegeket, hanem egységében kezelik a dokumentumokat és azok egyes mondatait képesek rangsorolni fontosság szerint. Mi pedig ezt követően meghatározhatjuk, hogy a rangsor éléről hány mondatra vagyunk kíváncsiak. Ezek közül a megoldások közül az egyik legnépszerűbb a Textrank algoritmus, amelyet mi is használtunk. A Textrank egy gráf alapú rangsorolási módszer, amely esetében a csúcsok az egyes mondatokat jelentik az élek a csúcsok (mondatok) között pedig az egyes mondatok közötti tartalmi átfedést jelképezik. Ezt a gráfot aztán a Pagerank algoritmus segítségével kiértékeli, majd meghatározza az adott szövegen belüli legrelevánsabb mondatokat, amiket felhasználhatunk a kivonathoz. Érdekesség, hogy a Pagerank algoritmust a Google alapítói fejlesztették ki a 90-es évek végén, és sokáig ez az algoritmus volt, ami a Google keresések során a találati listában lévő találatok sorrendjét meghatározta. Ma már természetesen számos más algoritmus is dolgozik a találati listák összeállításán.
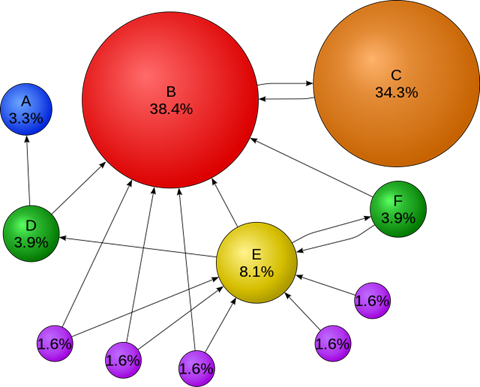
Példa egy Google algoritmusa által használt PageRank hálózatra. Az egyes körök weboldalakat jelentenek, a közöttük lévő nyilak pedig az egymásra történő hivatkozást. Az egyes százalékok és a körök mérete pedig az értékrangsort fejezik ki. A Textrank algoritmus ezt a megoldást használja fel annyiban, hogy a körök mondatokat jelentenek, a közöttük lévő kapcsolat pedig a tartalmi átfedéseket hivatottak jelezni, és ebből számol az algoritmus minden mondatra egy értéket a szövegen belül. Forrás: Wikipédia
Kivonat hosszának meghatározása
A vektorizáláson és a különböző nem-felügyelt tanítási módszereken túl további fontos szempont a kivonatok minőségének szempontjából, hogy milyen hosszú (hány karakterből vagy hány mondatból) álló összefoglalót szeretnénk megjeleníteni az egyes dokumentumokhoz. Ennek optimális meghatározásához számos eljárást lehet használni, amelyek közül többet mi is kipróbáltunk a fejlesztés során.
Az első lehetséges mód a kézi, fix meghatározás, amikor is kézzel beállítjuk, hogy pontosan hány mondatot szeretnénk visszakapni minden egyes dokumentum esetében. Ebben az esetben a kérdés az, hogy mennyi legyen ez a mondatszám. Ennek eldöntéséhez a Wolters Kluwer Hungary Kft. jogász szakértői kézzel kivonatoltak 150 bírósági határozatot, ahol a szerkesztők feladata az volt, hogy válasszák ki a határozatokból azokat a mondatokat, amelyek az ügy szempontjából fontosak és segíthetnek a határozatot nem ismerő felhasználónak eldönteni, hogy az számára releváns lehet-e. A kézi kivonatok elkészítése után megvizsgáltuk a kivonatok mondatszámának eloszlását az egyes dokumentumok esetében és a következő megállapításokra jutottunk: a legnagyobb számosságban a 3 mondatos kivonatok fordultak elő, emellett is túlsúlyban voltak a rövid, pár mondatos kivonatok, és ugyan volt pár hosszabb, akár 13 mondatos kivonat is, de a kivonatok mondatszámának átlaga így is mindössze 3,72 lett. Ezért a kézi beállításnál 4 mondatra állítottuk be a kivonatok fix hosszúságát.
A másik meghatározási mód, amit kipróbáltunk az ideális mondatszám meghatározáshoz, az általunk empirikusnak elnevezett megoldás volt. Ez abból a feltételezésből indult ki, hogy a hosszabb dokumentumokhoz valószínűleg hosszabb kivonatoknak kell tartoznia, mert több lehet bennük a tartalmukat önmagában is jól jellemző mondat. Ehhez megnéztük, hogy a WK szerkesztők által kézzel kivonatolt határozatok esetében átlagosan hány mondat hosszúságúak az adott mondatszámú kivonatokhoz tartozó dokumentumok, majd ezen pontokra illesztettünk egy egyenest, ahogy ez a lenti ábrán is látszódik. Látható, hogy ahogy növekszik a mondatoknak a hossza, úgy ezzel a beállítással egyre hosszabb kivonatokat kapunk azzal a feltétellel, hogy a kivonat legalább egy és maximum 10 mondat lehet, mert tudtuk, hogy annál hosszabbat a Jogtár felületén nem érdemes megjeleníteni, mivel akkor a találati lista átláthatatlanná válik.
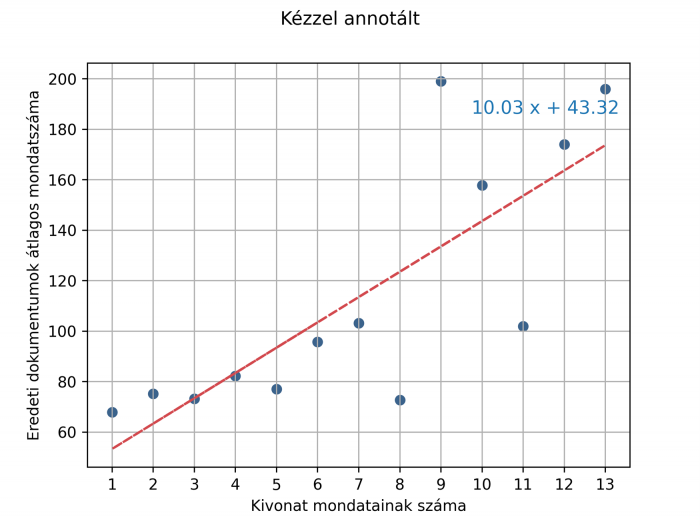
Az ábra az egyes kivonatszámosságokhoz tartozó dokumentumok átlagos mondatszámát mutatja be, amin látszik, hogy az átlagosan hosszabb dokumentumokhoz az emberi kivonatolók több mondatos kivonatokat készítettek.
Végül pedig még kipróbáltuk a kivonat optimális mondatszámának automatikus, algoritmus általi meghatározását is. Ahogy fentebb is említettük, a K-Means algoritmust képesek voltunk továbbfejleszteni úgy, hogy a szöveg belső szabályszerűségeinek felismerésével megbecsülje, hogy az adott dokumentumon belül hány darab különböző témakör található. Ezzel a megoldással minden egyes dokumentum esetében meg tudjuk határozni, hogy mennyi lenne az ideális témakörszám a gép szerint, függetlenül a szöveg hosszúságától, és beállítani, hogy annyi mondatot válasszunk ki, ahányat az algoritmus javasol. A kivonatok mondatszámának optimális meghatározásáról az idei Magyar Számítógépes Nyelvészeti Konferencián részletesebben is prezentáltunk, illetve publikáltunk. Aki mélyebben is érdeklődik a téma iránt, megtalálja a tanulmányunkat itt.
Nem releváns részek kiszűrése az eredeti szövegből
Az eddigieken felül fontos vizsgálati szempont lehet, hogy ha tudjuk, hogy a dokumentumoknak vannak olyan szövegegységei, amelyek mondatait biztos nem szeretnénk szerepeltetni az elkészült kivonatokban, akkor azokat a szövegegységeket érdemes kiszűrni már előre a lehetséges kivonat mondatai közül, így csökkentve az elkészült összefoglalók zajosságát. A fejlesztés során a következő szövegegységek kiszűrésének hatását vizsgáltuk meg:
A kivonat minőségét befolyásoló tényezők és az egyes módszerek azonosítását követően pedig már “csak” annyi volt a feladatunk, hogy megnézzük, hogy az egyes módszerek hogyan teljesítenek a bírósági határozatokon, és melyek készítenek olyan kivonatokat, amelyek a legrelevánsabb mondatokat emelik ki az egyes szövegekből. Fontos továbbá, hogy a tényezőket nem egyesével kellett értékelni, hanem egymással kölcsönhatásban, hisz az egyes vektorizálási módok hathatnak arra például, hogy az egyes klaszterezési és rangsorolási algoritmusok hogyan működnek, emiatt lehet, hogy az egyik vektorizálási módnál az egyik, másiknál a másik lesz jobb. Így a fentebb bemutatott módszereket egymással kombinálva kellett megvizsgálni. A kivonatkészítés ráadásul egy meglehetősen szubjektív műfaj, különböző emberek valószínűleg különböző mondatokat fognak relevánsnak tartani egy szövegben, ezért a kivonatok minőségének mérése sem egy triviális probléma. A cikksorozat következő részében bemutatjuk, hogy milyen metrikák léteznek a kivonatok minőségének ellenőrzésére, és hogy az általunk fejlesztett megoldások ezek alapján milyen eredményeket értek el.
Ez az írás a Wolters Kluwer Hungary Kft. és a MONTANA Tudásmenedzsment Kft. közös, automatikus összefoglalót készítő algoritmusának fejlesztését bemutató cikksorozatának második része. Az előző részben bemutattuk az automatikus kivonatokkal megoldani szánt problémákat, valamint az automatikus összefoglaló készítő algoritmusok típusait. A cikksorozat következő, záró részében pedig bemutatjuk az összefoglalók minőségének mérési módszereit és az elkészült kivonatkészítő algoritmus eredményeit.
Az algoritmus által készített összefoglalók már megtekinthetőek a Jogtár felületén is. Emellett értékelni is lehet a gép által készített kivonatokat, illetve szöveges visszajelzést is lehet küldeni, amiknek azért örülünk, mert további impulzusokat adhatnak a kivonatok minőségének, illetve ezáltal a felhasználói élmény javításához.
![]()
![]()
A cikk szerzői: