A gép forog, az alkotó pihen: a végeredmény – egy jogi címkéző algoritmus fejlesztése a kulisszák mögött V.
Ez a cikk több mint egy éve került publikálásra. A cikkben szereplő információk a megjelenéskor pontosak voltak, de mára elavultak lehetnek.
A jogi szöveg önmagában egy olyan különleges nyelv, amire kihívás a gépi tanulás módszereit alkalmazni – de egyáltalán nem lehetetlen. A cikksorozat záró részében megmutatjuk milyen további eredményeket értünk el, és milyen megállapításokat tettünk az anonimizált bírósági határozatok kategorizálásával kapcsolatban.
Elérkeztünk sorozatunk záró részéhez: akik figyelemmel követték eddig a cikkeket, megtudhatták, hogy milyen, a jogászi, ügyvédi kutatómunkát érintő problémából indultunk ki, és hogyan adtunk erre egy megoldást különböző módszerekkel, eszközökkel kísérletezve.
Egy ilyen, gépi tanuláson alapuló fejlesztés során mindig kérdés, hogy milyen eredményeket kell figyelembe venni az algoritmus teljesítményének értékeléséhez, ezért a legutóbbi részben bemutattuk, hogy hogyan határoztuk meg a gépi tanításhoz szükséges minimális dokumentumszámot, illetve hogy milyen eredményeket értünk el a jogi szöveg augmentálása (tehát mesterséges adatok létrehozása), valamint a negatív szűrés és a validált pozitív tanítóadattal történő iteratív tanítás során, és hogy hogyan értékeltük ki a címkézés hatékonyságát kézzel felcímkézett adatokon. Ebben az utolsó részben pedig bemutatjuk a további eredményeket, és összefoglaljuk a fejlesztés tapasztalatait.
Eredmények II.
Az algoritmus kiértékelése egy kísérleten keresztül
Ahogy az előző cikksorozatban bemutattuk, egy kísérlet keretében megmértük, hogy az emberi címkézők milyen teljesítményt érnek el a határozatok pertárgy szerinti kategorizálása során, ugyanis kíváncsiak voltunk az algoritmusnak nemcsak az egyéni teljesítményére, hanem arra is, hogy hogyan teljesít ugyanolyan emberi munkához viszonyítva. Ugyanis egy mesterséges intelligencia fejlesztés értékét végső soron az határozza meg, hogy mennyire képes javítani az emberi munkavégzés hatékonyságát.
A kísérlethez kiválasztottunk 220 darab, jogi szakértők által a kiértékeléshez előre felcímkézett anonimizált bírósági határozatot olyan módon, hogy azok nagyjából lefedjék a teljes adathalmaz arányait jogterület, dokumentumok hosszúsága, és bonyolultsága alapján. A kísérletben részt vett hat Jogtár szerkesztő is (a fejlesztést a Jogtárat kiadó Wolters Kluwer Hungary Kft., és a Montana Tudásmenedzsment Kft. végezte), akiknek a mindennapi feladata az, hogy határozatokat annotáljanak különböző metaadatok alapján. A feladatuk az volt, hogy 3 óra alatt minél több dokumentumot felcímkézzenek a 220 darabból. A kísérlet célja az volt, hogy modellezzük a valódi címkézési munka monotonitását, ami az ilyen típusú munkák legfőbb negatívuma. A kísérletben résztvevők két csoportra voltak osztva: az egyik csoport csak magukat a dokumentumokat kapta meg, míg a másik csoport megkapta azt is, hogy az algoritmus előzetesen milyen címkéket ajánlott arra a határozatra.
A teljesítmények pontos méréséhez bevezettünk egy pontrendszert is. A pontrendszer lényege az volt, hogy kiegyenlítsük a címkék információtartalmában és általánosságában/specifikusságában lévő különbségeket, ezért minden egyes címke 1 pontot, 5 pontot vagy 10 pontot ért. Például a „Munkaviszony megszüntetése” címke, ami a munkajogi jogterülethez tartozó címkék 30%-át lefedte, kis információértékkel bír, ezért annak megtalálása csak 1 pontot ér, míg az „Orvosi műhiba” egy viszonylag ritka címke, ezért 10 pontot ért. Így a 220 dokumentumból, illetve azok címkéiből összesen 1020 pontot lehetett összegyűjteni a címkézés során.
A kísérlet kiértékelésével azt a nem várt eredményt kaptuk, hogy azok a szerkesztők, akik felhasználhatták az algoritmus segítségét, kevesebb pontot értek el összesen (245), mint azok, akik csak a határozat szövegét kapták meg (342). A legtöbb pontot pedig az automatikus kategorizáló, vagyis a gép érte el (490). Ha viszont azt nézzük, hogy egy darab dokumentumból átlagosan mekkora információértéket nyertek ki a különböző csoportok, akkor azt láthatjuk, hogy azok, akik gépi segítséget használtak, 50%-kal több információt nyertek ki, mint a szerkesztők másik csoportja, vagy a gép önmagában. Ezek az eredmények azt mutatják, hogy azok a szerkesztők, akik gépi segítséget kaptak lassabban címkézték a dokumentumokat, ezért kevesebb dokumentumig jutottak el a kísérlet során, mint azok, akik nem kaptak előre címkézett dokumentumokat. Viszont az is látszik, hogy ez amiatt történt így, mert ezek a szerkesztők az előre felajánlott címkék miatt alaposabban nézték át az egyes határozatokat, és a gépi segítségnek köszönhetően nagyobb arányban is találták meg a ritkább címkéket. Ezzel szemben a szerkesztők másik csoportja, akik előre felajánlott címkék nélkül dolgoztak, mindent egybevetve sokkal általánosabb címkéket tettek a dokumentumokra, és így gyorsabban haladtak, tehát összességében több pontot értek el, de egy dokumentumra vetítve kevesebb információt nyertek ki, ahogy az alábbi ábra is mutatja.
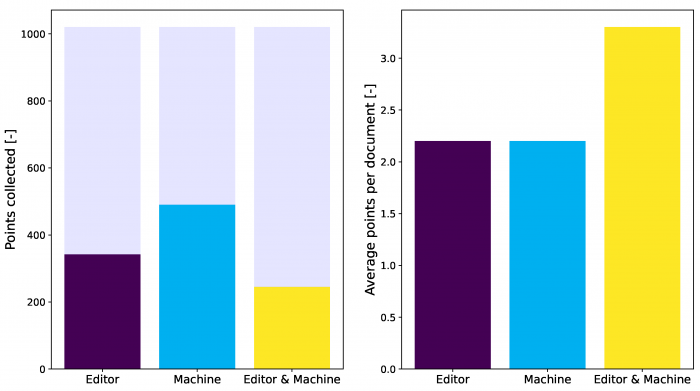
A teljesítmények összehasonlítása: baloldalt az összesen összegyűjtött pontok, jobboldalt az átlagos pontszámok egy dokumentumra nézve
Összefoglalás
A bemutatott fejlesztésünk két lényeges aspektusában különbözött más korábbi szövegbányászati, illetve mesterséges intelligencia alapú fejlesztésektől: egyrészt jogi adathalmazon fejlesztettünk le egy multi-label klasszifikáló algoritmust, másrészt nem állt rendelkezésünkre előzetesen megfelelő mennyiségű előre felcímkézett tanítóadat – ami ahogy azt bemutattuk, alapvető követelmény egy felügyelt tanításon alapuló gépi tanulásos fejlesztésnél.
Emellett pedig a jogi szöveg jellemzőiből fakadó sajátosságokkal is meg kellett küzdenünk: a legtöbb kihívással teli címkék azok voltak, ahol a kategória nem volt független más kategóriáktól. Erre jó példa a „Bűnpártolás” címke, ugyanis a bűnpártolás tényállása ritkán szerepel önmagában egy határozatban, ugyanis a bűnpártoláshoz szükség van más bűncselekményre is, amihez járulékosan tapadhat. Ezért az ilyen határozatok gyakran tartalmaznak olyan más jogi kulcsszavakat, amelyek más kategóriákhoz kapcsolódnak, ezzel nehezítve a tanítási folyamatot az algoritmus számára. Az olyan kategóriák szintén problematikusak a gépi tanulásos eljárások számára, amelyek szemantikailag hasonlóak, mint például a korábbi cikkekben már említett „Szállítási és szállítmányozási szerződés„, illetve „Nemzetközi árufuvarozás, szállítmányozás” címkék esete.
A fejlesztés során különböző gépi tanulási eljárásokat is teszteltünk egy kiválasztott címkén, azért, hogy a különböző lehetséges megoldások teljesítményét megmérhessük. A kiválasztott címke a „Munkaviszony megszüntetése” lett, ugyanis abból elegendő mennyiségű tanítóadat állt rendelkezésünkre, hogy a különböző eljárásokat és mennyiségbeli különbségeket megnézhessük. Elsőként a különböző augmentálási megoldásokat vizsgáltuk meg, és arra jutottunk, hogy ugyan az easy data augmentation (EDA) elnevezésű eljárást rövid szövegek augmentálására fejlesztették ki és azon tesztelték, az eredményeink azt mutatják, hogy a viszonylag hosszú jogi szövegek bináris klasszifikáló modelljeinek kifejlesztésére is hasznos. Akkor érték el a legjobb F1 értéket ezzel kapcsolatban, amikor az algoritmust 50-100 közötti pozitív tanítóadaton tanítottuk. Emellett megnéztük, hogy mi az a minimális dokumentumszám, ami szükséges a tanításhoz, és arra jutottunk, hogy az optimális mennyiség kb. 50-100 dokumentum, de már 20 darab dokumentum esetében elérjük a minimálisan meghatározott 80% körüli F1 értéket.
Az algoritmus általános teljesítményét pedig két adathalmazon is megmértük. Az első adathalmazon, amikor csak az algoritmus teljesítményét néztük meg önmagában akkor arra jutottunk, hogy az algoritmus képes a dokumentumok 57,3%-át legalább részben jól felcímkézni. Ezeknek a hagyományos mérőszámoknak a hátulütője viszont, hogy keveset árul el az algoritmus használat közbeni teljesítményéről, és mivel a mi fejlesztésünk a Jogtár környezetébe készült, ezért kíváncsiak voltunk rá, hogy a gyakorlatban mennyire képes segíteni a szerkesztők munkáját. Ezért, ahogy fentebb is olvasható, végeztünk egy kisebb kísérletet, amivel erre a kérdésre kerestük a választ különböző nézőpontok szerint. A kutatás eredményei, ahogy arról egy korábbi cikksorozatban is beszámoltunk, egyrészt azt mutatták, hogy az algoritmus bizonyos mérőszámokban képes volt elérni a leginkább hozzáértő jogi szakértők címkézési teljesítményét, másrészt pedig azt, hogy a gépi tanulás képes jelentősen, esetenként akár 50%-kal is megnövelni a szerkesztők munkavégzésének hatékonyságát a gép és az ember eltérő tanulási görbéjének köszönhetően.
Végeredményben tehát az anonimizált bírósági határozatok bináris kategorizálására épülő multi-label megoldásunk nem okozott csalódást. Az eddig megjelent cikkekben bemutattuk, hogy milyen megfontolásokat kell figyelembe venni egy hasonló gépi tanuláson alapuló jogi informatikai fejlesztés során, illetve hogy a fejlesztés eredményének teljesítményét milyen különböző mérésekkel lehet meghatározni. A projekt során ráadásul mi is sok tapasztalattal gazdagodtunk a jogi szövegekkel kapcsolatos fejlesztések terén, így a fejlesztés következő fázisában ezekre a tapasztalatokra építve, egy, az adathalmaz statisztikai és nyelvészeti sajátosságaira részletesebben építő, szabályalapú kategóriarendszer létrehozásával az algoritmus eredményeit még jobban sikerült javítanunk. Hamarosan ezzel a fejlesztéssel kapcsolatban is egy cikksorozattal fogunk jelentkezni.
Ez a cikksorozat most véget ért. További fejlesztéseinkről, illetve más aktuális LegalTech témákról a továbbiakban is cikkekkel fogunk jelentkezni, ezért érdemes keddenként is a Jövő jogásza, illetve a Jogászvilág felületeit követni.


A kutatásról készült teljes, angol nyelvű tanulmány ingyenesen letölthető innen.
A tanulmány szerzői:
- Csányi Gergely Márk PhD, NLP mérnök, a Budapesti Műszaki és Gazdaságtudományi Egyetem Villamosmérnöki és Informatikai Karán doktorált, a MONTANA Tudásmenedzsment Kft. természetesnyelv-feldolgozási szakértője
- Vági Renátó, jogász, az Eötvös Loránd Tudományegyetem Állam- és Jogtudományi Karának Jog- és Társadalomelméleti Tanszékének doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. jogi informatikai szakértője
- Megyeri Andrea, a Wolters Kluwer Hungary Kft. innovációs és tartalomfejlesztési igazgatója
- Üveges István, a Szegedi Tudományegyetem Nyelvtudományi Doktori Iskolájának doktorandusz hallgatója, valamint a MONTANA Tudásmenedzsment Kft. számítógépes nyelvészeti szakértője
- Vadász János Pál PhD, a Nemzeti Közszolgálati Egyetem Információs Társadalom Kutatóintézet, valamint a Nemzeti Közszolgálati Egyetem Digitális Jogalkalmazás Kutatócsoport kutatója, a MONTANA Tudásmenedzsment Kft. ügyvezető igazgatója
- Orosz Tamás PhD, szoftverfejlesztő mérnök
- Nagy Dániel, a MONTANA Tudásmenedzsment Kft. szoftverfejlesztési üzletágának vezetője